搜索到
6
篇与
的结果
-
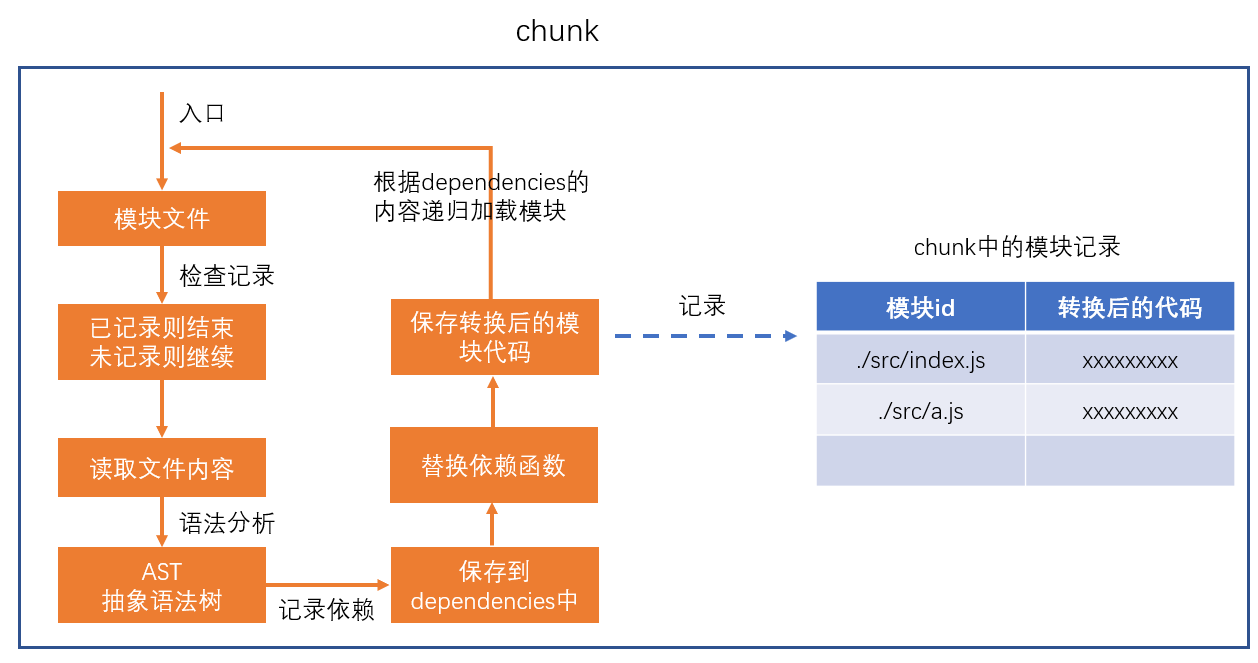
 webpack学习笔记 一、webpack安装与配置官网:https://www.webpackjs.com/npm i webpack webpack-cli // 运行 npx webpack基本配置默认情况下,webpack会读取webpack.config.js文件作为配置文件,也可以通过CLI参数--config来指定某个配置文件 // webpack的基本配置 module.exports = { // 编译模式 "development" | "production" mode: "development", // 配置源码地图 具体配置:https://www.webpackjs.com/configuration/devtool/ devtool: "source-map", // 入口 webpack从入口开始依赖解析 entry:{ // 属性名:chunk的名称, 属性值:入口模块(启动模块) main: "./src/index.js" }, // 出口配置 output: { // 公用的公共路径 / publicPath: "/", // 输出目录为 dist 默认为dist path: path.resolve(__dirname, "dist"), // js 输出到 dist/js/xxx filename: "js/[name].[chunkhash:5].js" }, // loader配置 运行时从从右到左,从下到上 module: { // 模块的匹配规则 rules: [ // 规则1 { // 正则表达式,匹配模块的路径 test: /index\.js$/, // 匹配到了之后,使用哪些加载器 use: ["./loaders/loader1", "./loaders/loader2"] }, // 规则2 { // 正则表达式,匹配模块的路径 test: /\.js$/, // 匹配到了之后,使用哪些加载器 use: ["./loaders/loader3", "./loaders/loader4"] } ] }, // 插件配置 运行顺序看内部生命周期钩子触发顺序,监听相同生命周期时从上到下(从左到右) plugins: [ new MyPlugin({ // 插件内部配置 }) ], // 开发处理器配置 需要安装webpack-dev-server 只在开发环境有效 devServer: { port: 8080, // 自动打开网页 open: true, // 开启热替换HMR 需要在代码里写入 module.hot.accept(); 接受热更新 hot:true, // 代理规则 proxy: { "/api": { target: "http://blog.imtwa.com", //更改请求头中的host和origin changeOrigin: true } } }, // 优化配置 optimization: { splitChunks: { // 分包配置 chunks: "all", // 缓存组配置 cacheGroups:{ } }, }, resolve: { alias: { // 别名 @ = src目录 "@": path.resolve(__dirname, "src"), // 别名 _ = 工程根目录 _: __dirname, }, }, stats: { // 打包时使用不同的颜色区分信息 colors: true, // 打包时不显示具体模块信息 modules: false, // 打包时不显示入口模块信息 entrypoints: false, // 打包时不显示子模块信息 children: false, } };二、webpack打包流程webpacke是实现模块化的重要构建工具,它是将开发时态的代码转成运行时态代码,所以webpack不会影响代码的开发和运行,只会在打包时影响打包过程。所以webpack是运行在node环境下,与浏览器环境无关。初始化此阶段,webpack会将CLI参数、配置文件、默认配置进行融合,形成一个最终的配置对象。编译1、创建chunkchunk是webpack在内部构建过程中的一个概念,译为块,它表示通过某个入口找到的所有依赖的统称。根据入口模块(默认为./src/index.js)创建一个chunk每个chunk都有至少两个属性:name:默认为mainid:唯一编号,开发环境和name相同,生产环境是一个数字,从0开始2、构建所有依赖模块webpack只能分析js代码,将js代码读取后进行AST抽象语法树分析,找到每个代码的依赖,并转换代码。loader在做AST前生效,处理源代码。AST在线测试工具:https://astexplorer.net/3、产生chunk assets在第二步完成后,chunk中会产生一个模块列表,列表中包含了模块id和模块转换后的代码接下来,webpack会根据配置为chunk生成一个资源列表,即chunk assets,资源列表可以理解为是生成到最终文件的文件名和文件内容4、合并chunk assets将多个chunk的assets合并到一起,并产生一个总的hash输出webpack将利用node中的fs模块,根据编译产生的总的assets,生成相应的文件。涉及术语module:模块,分割的代码单元,webpack中的模块可以是任何内容的文件,不仅限于JSchunk:webpack内部构建模块的块,一个chunk中包含多个模块,这些模块是从入口模块通过依赖分析得来的bundle:chunk构建好模块后会生成chunk的资源清单,清单中的每一项就是一个bundle,可以认为bundle就是最终生成的文件hash:最终的资源清单所有内容联合生成的hash值chunkhash:chunk生成的资源清单内容联合生成的hash值chunkname:chunk的名称,如果没有配置则使用mainid:通常指chunk的唯一编号,如果在开发环境下构建,和chunkname相同;如果是生产环境下构建,则使用一个从0开始的数字进行编号三、loaderloader处理在读取到文件内容之后,发生在AST抽象语法树之前。loader的功能定位是转换代码,因为webpack只能对js代码进行抽象语法树分析,所以需要在loader阶段引入对图片、css等处理成js代码。也可以对源代码进行修改,如babel-loader等。loader执行顺序是从下到上、从右到左,上一个loader处理后再交给下一个loader。常用的loader// 使用 postcss 处理 css https://postcss.org/ postcss-loader // 解析 CSS 文件中的 import 和 url() css-loader // 将 CSS 插入到 DOM 中 style-loader // css 样式打包成一个文件 // 该 loader 负责记录要生成的 css 文件的内容 // 同时导出开启 css-module 后的样式对象 mini-css-extract-plugin.loader // 各种图片、字体文件,均交给 url-loader 处理 url-loader // 转换js代码,用于适配各版本浏览器 https://www.babeljs.cn/ babel-loader四、pluginplugin的本质是一个带有apply方法的对象,嵌入到webpack的编译流程中的节点进行处理。执行顺序看节点,同节点的按配置中从上到下、从左到右。apply函数会在初始化阶段,创建好Compiler对象后运行。compiler对象是在初始化阶段构建的,整个webpack打包期间只有一个compiler对象,后续完成打包工作的是compiler对象内部创建的compilation。apply方法会在创建好compiler对象后调用,并向方法传入一个compiler对象compiler对象提供了大量的钩子函数(hooks,可以理解为事件),plugin的开发者可以注册这些钩子函数,参与webpack编译和生成。class MyPlugin{ apply(compiler){ compiler.hooks.事件名称.事件类型(name, function(compilation){ //事件处理函数 }) } }事件名称即要监听的事件名,即钩子名,所有的钩子:https://www.webpackjs.com/api/compiler-hooks事件类型这一部分使用的是 Tapable API,这个小型的库是一个专门用于钩子函数监听的库。它提供了一些事件类型:tap:注册一个同步的钩子函数,函数运行完毕则表示事件处理结束tapAsync:注册一个基于回调的异步的钩子函数,函数通过调用一个回调表示事件处理结束tapPromise:注册一个基于Promise的异步的钩子函数,函数通过返回的Promise进入已决状态表示事件处理结束处理函数处理函数有一个事件参数compilation。常用的plugin// 清除输出目录文件 clean-webpack-plugin // 自动生成html文件 并引入打包后的js html-webpack-plugin // 复制静态资源到输出目录 copy-webpack-plugin // 将css文件打包成一个文件 // 和mini-css-extract-plugin.loader合用 mini-css-extract-pluginwebpack内置插件// 全局常量定义插件,使用该插件通常定义一些常量值 DefinePlugin // 可以为每个chunk生成的文件头部添加一行注释 // 一般用于添加作者、公司、版权等信息 BannerPlugin // 自动加载模块,不用手动import 或 require // 写法 /* new webpack.ProvidePlugin({ $: 'jquery', _: 'lodash' }) */ ProvidePlugin五、性能优化性能优化可以从三个方向入手构建性能传输性能运行性能构建性能这里所说的构建性能,是指在开发阶段的构建性能,降低从打包开始,到代码效果呈现所经过的时间。1、减少模块解析配置module.noParse,对第三方或打包好的模块不进行解析。2、优化loader性能有一些库不用经过特定的loader解析,如配置exclude: /lodash/,在使用babel-loader时不解析lodash库。module.exports = { module: { rules: [ { test: /\.js$/, exclude: /lodash/, use: "babel-loader" } ] } }3、开启热替换默认情况下,webpack-dev-server不管是否开启了热更新,当重新打包后,都会调用location.reload刷新页面。但如果运行了module.hot.accept(),将改变这一行为。module.hot.accept()的作用是让webpack-dev-server通过socket管道,把服务器更新的内容发送到浏览器。浏览器将不在刷新重新请求整个模块,而是只请求发送变化的模块。devServer:{ hot:true // 开启HMR } // 并在js中加入下面代码 if(module.hot){ // 是否开启了热更新 module.hot.accept() // 接受热更新 }传输性能传输性能是指,打包后的JS代码传输到浏览器经过的时间。在优化传输性能时要考虑到:总传输量:所有需要传输的JS文件的内容加起来,就是总传输量,重复代码越少,总传输量越少。文件数量:当访问页面时,需要传输的JS文件数量,文件数量越多,http请求越多,响应速度越慢。浏览器缓存:JS文件会被浏览器缓存,被缓存的文件不会再进行传输。1、手动分包将不依赖其他模块的文件打包成公共模块,公共模块会被打包成为动态链接库(dll Dynamic Link Library),并生成资源清单。后续打包时webpack分析到引用的模块在资源清单中,就不会打包该模块。打包公共模块是一个独立的打包过程,在打包时利用DllPlugin生成资源清单。module.exports = { mode: "production", entry: { jquery: ["jquery"], lodash: ["lodash"] }, output: { filename: "dll/[name].js", library: "[name]" // 每个bundle暴露的全局变量名 }, plugins: [ new webpack.DllPlugin({ // 这里不参与打包后的代码运行,不用放到输出目录中 path: path.resolve(__dirname, "dll", "[name].manifest.json"), name: "[name]" }) ] };打包完成后,需要在页面手动引入公共模块的js文件。并在主代码打包时引入打包好的资源清单new webpack.DllReferencePlugin({ manifest: require("./dll/jquery.manifest.json") }), new webpack.DllReferencePlugin({ manifest: require("./dll/lodash.manifest.json") })手动打包的过程: 1. 开启`output.library`暴露公共模块 2. 用`DllPlugin`创建资源清单 3. 用`DllReferencePlugin`使用资源清单 手动打包的注意事项: 1. 资源清单不参与运行,可以不放到打包目录中 2. 记得手动引入公共JS,以及避免被删除 3. 不要对小型的公共JS库使用 优点: 1. 极大提升自身模块的打包速度 2. 极大的缩小了自身文件体积 3. 有利于浏览器缓存第三方库的公共代码 缺点: 1. 使用非常繁琐 2. 如果第三方库中包含重复代码,则效果不太理想2、自动分包配置webpack分包策略,webpack可以根据分包策略自动进行分包。webpack提供了optimization配置项,用于配置一些优化信息,其中splitChunks是分包策略的配置。module.exports = { optimization: { splitChunks: { // 分包策略 chunks: "all" } } }chunks:从chunk中分离chunk,实现分包。all: 对于所有的chunk都要应用分包策略async:【默认】仅针对异步chunk应用分包策略initial:仅针对普通chunk应用分包策略maxSize:控制包的最大字节数,超过后尽可能分包(因为分包是按模块划分,单一模块超过字节后无法再分)minChunks:一个模块被多少个chunk使用时,才会进行分包,默认值1缓存组配置之前配置的分包策略是全局的,而实际上,分包策略是基于缓存组的。每个缓存组提供一套独有的策略,webpack按照缓存组的优先级依次处理每个缓存组,被缓存组处理过的分包不需要再次分包。默认情况下,webpack提供了两个缓存组:module.exports = { optimization:{ splitChunks: { //全局配置 cacheGroups: { // 属性名是缓存组名称,会影响到分包的chunk名 // 属性值是缓存组的配置,缓存组继承所有的全局配置,也有自己特殊的配置 vendors: { // 当匹配到相应模块时,将这些模块进行单独打包 test: /[\\/]node_modules[\\/]/, // 缓存组优先级,优先级越高,该策略越先进行处理,默认值为0 priority: -10 }, default: { // 覆盖全局配置,将最小chunk引用数改为2 minChunks: 2, // 优先级 priority: -20, // 重用已经被分离出去的chunk reuseExistingChunk: true } } } } }修改缓存组以实现css公共样式抽离module.exports = { optimization: { splitChunks: { chunks: "all", cacheGroups: { styles: { test: /\.css$/, // 匹配样式模块 minSize: 0, // 覆盖默认的最小尺寸,这里仅仅是作为测试 minChunks: 2 // 覆盖默认的最小chunk引用数 } } } }, module: { rules: [{ test: /\.css$/, use: [MiniCssExtractPlugin.loader, "css-loader"] }] }, plugins: [ new CleanWebpackPlugin(), new HtmlWebpackPlugin({ template: "./public/index.html", chunks: ["index"] }), new MiniCssExtractPlugin({ filename: "[name].[hash:5].css", // chunkFilename是配置来自于分割chunk的文件名 chunkFilename: "common.[hash:5].css" }) ] }这两种分包方法所能分的最小包还是一个模块的大小,下面使用代码压缩和tree shaking将会减少模块的体积。3、代码压缩webpack自动集成了Terser https://terser.org/,可以减少代码体积;破坏代码的可读性,提升破解成本。用法:const TerserPlugin = require('terser-webpack-plugin'); const OptimizeCSSAssetsPlugin = require('optimize-css-assets-webpack-plugin'); module.exports = { optimization: { // 是否要启用压缩,默认情况下,生产环境会自动开启 minimize: true, minimizer: [ // 压缩时使用的插件,可以有多个 new TerserPlugin(), new OptimizeCSSAssetsPlugin() ], }, };4、tree shakingtree shaking可以通过分析模块间的依赖关系,自动去除没有用到的模块内容,从而大大减少了打包体积。但是tree shaking的模块分析依赖es6的模块分析,es的import绑定的变量是不可变的,更加稳定,所以在使用第三方库时,需要选择es6版本,如lodash-es。同时,在书写导入语句时,尽量分块导出、按需导入。使用export xxx导出,而不使用export default {xxx}导出使用import {xxx} from "xxx"导入,而不使用import xxx from "xxx"导入webpack2开始内置了tree shaking,在打包生产环境中会自动开启。5、懒加载使用import()动态引入一个模块,webpack会将模块打包成异步包,等到运行该语句时动态加载js。/* webpackChunkName:"lodash" */是修改包的名字。btn.onclick = async function() { //动态加载 //import 是ES6的草案 //浏览器会使用JSOP的方式远程去读取一个js模块 //import()会返回一个promise (* as obj) // const { chunk } = await import(/* webpackChunkName:"lodash" */"lodash-es"); const result = chunk([3, 5, 6, 7, 87], 2); console.log(result); }; 其它优化1、ESlint使用ESLint可以检查代码格式与质量,在开发阶段编写优雅的代码。2、bundle analyzerbundle-analyzer可以分析打包结果,生成图形化的界面。
webpack学习笔记 一、webpack安装与配置官网:https://www.webpackjs.com/npm i webpack webpack-cli // 运行 npx webpack基本配置默认情况下,webpack会读取webpack.config.js文件作为配置文件,也可以通过CLI参数--config来指定某个配置文件 // webpack的基本配置 module.exports = { // 编译模式 "development" | "production" mode: "development", // 配置源码地图 具体配置:https://www.webpackjs.com/configuration/devtool/ devtool: "source-map", // 入口 webpack从入口开始依赖解析 entry:{ // 属性名:chunk的名称, 属性值:入口模块(启动模块) main: "./src/index.js" }, // 出口配置 output: { // 公用的公共路径 / publicPath: "/", // 输出目录为 dist 默认为dist path: path.resolve(__dirname, "dist"), // js 输出到 dist/js/xxx filename: "js/[name].[chunkhash:5].js" }, // loader配置 运行时从从右到左,从下到上 module: { // 模块的匹配规则 rules: [ // 规则1 { // 正则表达式,匹配模块的路径 test: /index\.js$/, // 匹配到了之后,使用哪些加载器 use: ["./loaders/loader1", "./loaders/loader2"] }, // 规则2 { // 正则表达式,匹配模块的路径 test: /\.js$/, // 匹配到了之后,使用哪些加载器 use: ["./loaders/loader3", "./loaders/loader4"] } ] }, // 插件配置 运行顺序看内部生命周期钩子触发顺序,监听相同生命周期时从上到下(从左到右) plugins: [ new MyPlugin({ // 插件内部配置 }) ], // 开发处理器配置 需要安装webpack-dev-server 只在开发环境有效 devServer: { port: 8080, // 自动打开网页 open: true, // 开启热替换HMR 需要在代码里写入 module.hot.accept(); 接受热更新 hot:true, // 代理规则 proxy: { "/api": { target: "http://blog.imtwa.com", //更改请求头中的host和origin changeOrigin: true } } }, // 优化配置 optimization: { splitChunks: { // 分包配置 chunks: "all", // 缓存组配置 cacheGroups:{ } }, }, resolve: { alias: { // 别名 @ = src目录 "@": path.resolve(__dirname, "src"), // 别名 _ = 工程根目录 _: __dirname, }, }, stats: { // 打包时使用不同的颜色区分信息 colors: true, // 打包时不显示具体模块信息 modules: false, // 打包时不显示入口模块信息 entrypoints: false, // 打包时不显示子模块信息 children: false, } };二、webpack打包流程webpacke是实现模块化的重要构建工具,它是将开发时态的代码转成运行时态代码,所以webpack不会影响代码的开发和运行,只会在打包时影响打包过程。所以webpack是运行在node环境下,与浏览器环境无关。初始化此阶段,webpack会将CLI参数、配置文件、默认配置进行融合,形成一个最终的配置对象。编译1、创建chunkchunk是webpack在内部构建过程中的一个概念,译为块,它表示通过某个入口找到的所有依赖的统称。根据入口模块(默认为./src/index.js)创建一个chunk每个chunk都有至少两个属性:name:默认为mainid:唯一编号,开发环境和name相同,生产环境是一个数字,从0开始2、构建所有依赖模块webpack只能分析js代码,将js代码读取后进行AST抽象语法树分析,找到每个代码的依赖,并转换代码。loader在做AST前生效,处理源代码。AST在线测试工具:https://astexplorer.net/3、产生chunk assets在第二步完成后,chunk中会产生一个模块列表,列表中包含了模块id和模块转换后的代码接下来,webpack会根据配置为chunk生成一个资源列表,即chunk assets,资源列表可以理解为是生成到最终文件的文件名和文件内容4、合并chunk assets将多个chunk的assets合并到一起,并产生一个总的hash输出webpack将利用node中的fs模块,根据编译产生的总的assets,生成相应的文件。涉及术语module:模块,分割的代码单元,webpack中的模块可以是任何内容的文件,不仅限于JSchunk:webpack内部构建模块的块,一个chunk中包含多个模块,这些模块是从入口模块通过依赖分析得来的bundle:chunk构建好模块后会生成chunk的资源清单,清单中的每一项就是一个bundle,可以认为bundle就是最终生成的文件hash:最终的资源清单所有内容联合生成的hash值chunkhash:chunk生成的资源清单内容联合生成的hash值chunkname:chunk的名称,如果没有配置则使用mainid:通常指chunk的唯一编号,如果在开发环境下构建,和chunkname相同;如果是生产环境下构建,则使用一个从0开始的数字进行编号三、loaderloader处理在读取到文件内容之后,发生在AST抽象语法树之前。loader的功能定位是转换代码,因为webpack只能对js代码进行抽象语法树分析,所以需要在loader阶段引入对图片、css等处理成js代码。也可以对源代码进行修改,如babel-loader等。loader执行顺序是从下到上、从右到左,上一个loader处理后再交给下一个loader。常用的loader// 使用 postcss 处理 css https://postcss.org/ postcss-loader // 解析 CSS 文件中的 import 和 url() css-loader // 将 CSS 插入到 DOM 中 style-loader // css 样式打包成一个文件 // 该 loader 负责记录要生成的 css 文件的内容 // 同时导出开启 css-module 后的样式对象 mini-css-extract-plugin.loader // 各种图片、字体文件,均交给 url-loader 处理 url-loader // 转换js代码,用于适配各版本浏览器 https://www.babeljs.cn/ babel-loader四、pluginplugin的本质是一个带有apply方法的对象,嵌入到webpack的编译流程中的节点进行处理。执行顺序看节点,同节点的按配置中从上到下、从左到右。apply函数会在初始化阶段,创建好Compiler对象后运行。compiler对象是在初始化阶段构建的,整个webpack打包期间只有一个compiler对象,后续完成打包工作的是compiler对象内部创建的compilation。apply方法会在创建好compiler对象后调用,并向方法传入一个compiler对象compiler对象提供了大量的钩子函数(hooks,可以理解为事件),plugin的开发者可以注册这些钩子函数,参与webpack编译和生成。class MyPlugin{ apply(compiler){ compiler.hooks.事件名称.事件类型(name, function(compilation){ //事件处理函数 }) } }事件名称即要监听的事件名,即钩子名,所有的钩子:https://www.webpackjs.com/api/compiler-hooks事件类型这一部分使用的是 Tapable API,这个小型的库是一个专门用于钩子函数监听的库。它提供了一些事件类型:tap:注册一个同步的钩子函数,函数运行完毕则表示事件处理结束tapAsync:注册一个基于回调的异步的钩子函数,函数通过调用一个回调表示事件处理结束tapPromise:注册一个基于Promise的异步的钩子函数,函数通过返回的Promise进入已决状态表示事件处理结束处理函数处理函数有一个事件参数compilation。常用的plugin// 清除输出目录文件 clean-webpack-plugin // 自动生成html文件 并引入打包后的js html-webpack-plugin // 复制静态资源到输出目录 copy-webpack-plugin // 将css文件打包成一个文件 // 和mini-css-extract-plugin.loader合用 mini-css-extract-pluginwebpack内置插件// 全局常量定义插件,使用该插件通常定义一些常量值 DefinePlugin // 可以为每个chunk生成的文件头部添加一行注释 // 一般用于添加作者、公司、版权等信息 BannerPlugin // 自动加载模块,不用手动import 或 require // 写法 /* new webpack.ProvidePlugin({ $: 'jquery', _: 'lodash' }) */ ProvidePlugin五、性能优化性能优化可以从三个方向入手构建性能传输性能运行性能构建性能这里所说的构建性能,是指在开发阶段的构建性能,降低从打包开始,到代码效果呈现所经过的时间。1、减少模块解析配置module.noParse,对第三方或打包好的模块不进行解析。2、优化loader性能有一些库不用经过特定的loader解析,如配置exclude: /lodash/,在使用babel-loader时不解析lodash库。module.exports = { module: { rules: [ { test: /\.js$/, exclude: /lodash/, use: "babel-loader" } ] } }3、开启热替换默认情况下,webpack-dev-server不管是否开启了热更新,当重新打包后,都会调用location.reload刷新页面。但如果运行了module.hot.accept(),将改变这一行为。module.hot.accept()的作用是让webpack-dev-server通过socket管道,把服务器更新的内容发送到浏览器。浏览器将不在刷新重新请求整个模块,而是只请求发送变化的模块。devServer:{ hot:true // 开启HMR } // 并在js中加入下面代码 if(module.hot){ // 是否开启了热更新 module.hot.accept() // 接受热更新 }传输性能传输性能是指,打包后的JS代码传输到浏览器经过的时间。在优化传输性能时要考虑到:总传输量:所有需要传输的JS文件的内容加起来,就是总传输量,重复代码越少,总传输量越少。文件数量:当访问页面时,需要传输的JS文件数量,文件数量越多,http请求越多,响应速度越慢。浏览器缓存:JS文件会被浏览器缓存,被缓存的文件不会再进行传输。1、手动分包将不依赖其他模块的文件打包成公共模块,公共模块会被打包成为动态链接库(dll Dynamic Link Library),并生成资源清单。后续打包时webpack分析到引用的模块在资源清单中,就不会打包该模块。打包公共模块是一个独立的打包过程,在打包时利用DllPlugin生成资源清单。module.exports = { mode: "production", entry: { jquery: ["jquery"], lodash: ["lodash"] }, output: { filename: "dll/[name].js", library: "[name]" // 每个bundle暴露的全局变量名 }, plugins: [ new webpack.DllPlugin({ // 这里不参与打包后的代码运行,不用放到输出目录中 path: path.resolve(__dirname, "dll", "[name].manifest.json"), name: "[name]" }) ] };打包完成后,需要在页面手动引入公共模块的js文件。并在主代码打包时引入打包好的资源清单new webpack.DllReferencePlugin({ manifest: require("./dll/jquery.manifest.json") }), new webpack.DllReferencePlugin({ manifest: require("./dll/lodash.manifest.json") })手动打包的过程: 1. 开启`output.library`暴露公共模块 2. 用`DllPlugin`创建资源清单 3. 用`DllReferencePlugin`使用资源清单 手动打包的注意事项: 1. 资源清单不参与运行,可以不放到打包目录中 2. 记得手动引入公共JS,以及避免被删除 3. 不要对小型的公共JS库使用 优点: 1. 极大提升自身模块的打包速度 2. 极大的缩小了自身文件体积 3. 有利于浏览器缓存第三方库的公共代码 缺点: 1. 使用非常繁琐 2. 如果第三方库中包含重复代码,则效果不太理想2、自动分包配置webpack分包策略,webpack可以根据分包策略自动进行分包。webpack提供了optimization配置项,用于配置一些优化信息,其中splitChunks是分包策略的配置。module.exports = { optimization: { splitChunks: { // 分包策略 chunks: "all" } } }chunks:从chunk中分离chunk,实现分包。all: 对于所有的chunk都要应用分包策略async:【默认】仅针对异步chunk应用分包策略initial:仅针对普通chunk应用分包策略maxSize:控制包的最大字节数,超过后尽可能分包(因为分包是按模块划分,单一模块超过字节后无法再分)minChunks:一个模块被多少个chunk使用时,才会进行分包,默认值1缓存组配置之前配置的分包策略是全局的,而实际上,分包策略是基于缓存组的。每个缓存组提供一套独有的策略,webpack按照缓存组的优先级依次处理每个缓存组,被缓存组处理过的分包不需要再次分包。默认情况下,webpack提供了两个缓存组:module.exports = { optimization:{ splitChunks: { //全局配置 cacheGroups: { // 属性名是缓存组名称,会影响到分包的chunk名 // 属性值是缓存组的配置,缓存组继承所有的全局配置,也有自己特殊的配置 vendors: { // 当匹配到相应模块时,将这些模块进行单独打包 test: /[\\/]node_modules[\\/]/, // 缓存组优先级,优先级越高,该策略越先进行处理,默认值为0 priority: -10 }, default: { // 覆盖全局配置,将最小chunk引用数改为2 minChunks: 2, // 优先级 priority: -20, // 重用已经被分离出去的chunk reuseExistingChunk: true } } } } }修改缓存组以实现css公共样式抽离module.exports = { optimization: { splitChunks: { chunks: "all", cacheGroups: { styles: { test: /\.css$/, // 匹配样式模块 minSize: 0, // 覆盖默认的最小尺寸,这里仅仅是作为测试 minChunks: 2 // 覆盖默认的最小chunk引用数 } } } }, module: { rules: [{ test: /\.css$/, use: [MiniCssExtractPlugin.loader, "css-loader"] }] }, plugins: [ new CleanWebpackPlugin(), new HtmlWebpackPlugin({ template: "./public/index.html", chunks: ["index"] }), new MiniCssExtractPlugin({ filename: "[name].[hash:5].css", // chunkFilename是配置来自于分割chunk的文件名 chunkFilename: "common.[hash:5].css" }) ] }这两种分包方法所能分的最小包还是一个模块的大小,下面使用代码压缩和tree shaking将会减少模块的体积。3、代码压缩webpack自动集成了Terser https://terser.org/,可以减少代码体积;破坏代码的可读性,提升破解成本。用法:const TerserPlugin = require('terser-webpack-plugin'); const OptimizeCSSAssetsPlugin = require('optimize-css-assets-webpack-plugin'); module.exports = { optimization: { // 是否要启用压缩,默认情况下,生产环境会自动开启 minimize: true, minimizer: [ // 压缩时使用的插件,可以有多个 new TerserPlugin(), new OptimizeCSSAssetsPlugin() ], }, };4、tree shakingtree shaking可以通过分析模块间的依赖关系,自动去除没有用到的模块内容,从而大大减少了打包体积。但是tree shaking的模块分析依赖es6的模块分析,es的import绑定的变量是不可变的,更加稳定,所以在使用第三方库时,需要选择es6版本,如lodash-es。同时,在书写导入语句时,尽量分块导出、按需导入。使用export xxx导出,而不使用export default {xxx}导出使用import {xxx} from "xxx"导入,而不使用import xxx from "xxx"导入webpack2开始内置了tree shaking,在打包生产环境中会自动开启。5、懒加载使用import()动态引入一个模块,webpack会将模块打包成异步包,等到运行该语句时动态加载js。/* webpackChunkName:"lodash" */是修改包的名字。btn.onclick = async function() { //动态加载 //import 是ES6的草案 //浏览器会使用JSOP的方式远程去读取一个js模块 //import()会返回一个promise (* as obj) // const { chunk } = await import(/* webpackChunkName:"lodash" */"lodash-es"); const result = chunk([3, 5, 6, 7, 87], 2); console.log(result); }; 其它优化1、ESlint使用ESLint可以检查代码格式与质量,在开发阶段编写优雅的代码。2、bundle analyzerbundle-analyzer可以分析打包结果,生成图形化的界面。 -
vscode插件 因为换了几台电脑,每次都要重新安装vscode和插件,这里记录一下用到的插件和对应的配置。Chinese (Simplified) (简体中文) Languagevscode简体中文配置Live Server建立本地服务器,实时显示服务器端页面Remote Repositories查看远程仓库Code Runner执行node代码indent-rainbow缩进颜色显示Draw.io Integration绘图插件any-rule多种正则Regex Previewer检查正则ESLint检查js格式化Prettier - Code formatter格式化检查与修复GitLens — Git supercharged显示git提交CodeGeeX: AI Coding Assistant智谱ai编程助手Markdown Preview Enhancedmarkdown文件预览显示首选项 开启Enable Script Execution(js脚本执行) 启用目录F1 搜索 markdown preview enhanced: customize css 配置css样式/* Please visit the URL below for more information: */ /* https://shd101wyy.github.io/markdown-preview-enhanced/#/customize-css */ .markdown-preview.markdown-preview { // modify your style here // eg: background-color: blue; font-family: "consolas", "Noto Sans S Chinese"; font-size: 1em; } .markdown-img-description{ text-align: center; margin-top: -1em; color: #666;; margin-bottom: 2em; } html body img{ border:2px solid #ccc; } .markdown-p-center{ text-align: center; }F1 搜索 markdown preview enhanced: extend parser 配置jsconst scripts = ` <script> function setCurrent(){ const links = document.querySelectorAll(".md-sidebar-toc a") for(const link of links){ link.style.color=""; } const hash = location.hash; const a = document.querySelector('a[href="'+hash+'"]'); if(a){ a.style.color = "#f40"; } } setCurrent(); window.onhashchange = setCurrent; </script> `; var fs = require("fs"); module.exports = { onWillParseMarkdown: function(markdown) { return new Promise((resolve, reject) => { const reg = /\!\[(.*)\]\((\S+)\)/gm; markdown = markdown.replace(reg, function(match, g1, g2) { var width = "100%"; if (g1) { var w = g1.split("|"); if (w.length > 1) { width = w[1] + "px"; g1 = w[0]; } } return ` <p class="markdown-p-center"> <img src="${g2}" alt="${g1}" style="max-width:${width}"/> </p> <p class="markdown-img-description"> ${g1} </p> `; }); resolve(markdown); }); }, onDidParseMarkdown: function(html) { return new Promise((resolve, reject) => { return resolve(scripts + html); }); } };
-
mysql开发规范 1. 规范背景与目的MySQL数据库与 Oracle、 SQL Server 等数据库相比,有其内核上的优势与劣势。我们在使用MySQL数据库的时候需要遵循一定规范,扬长避短。本规范旨在帮助或指导RD、QA、OP等技术人员做出适合线上业务的数据库设计。在数据库变更和处理流程、数据库表设计、SQL编写等方面予以规范,从而为公司业务系统稳定、健康地运行提供保障。2. 设计规范2.1 数据库设计以下所有规范会按照【高危】、【强制】、【建议】三个级别进行标注,遵守优先级从高到低。对于不满足【高危】和【强制】两个级别的设计,审核人员应强制打回要求修改。2.1.1 库名【强制】库的名称必须控制在32个字符以内,相关模块的表名与表名之间尽量体现join的关系,如user表和user_login表。【强制】库的名称格式:业务系统名称_子系统名,同一模块使用的表名尽量使用统一前缀。【强制】一般分库名称命名格式是库通配名_编号,编号从0开始递增,比如wenda_001以时间进行分库的名称格式是“库通配名_时间”【强制】创建数据库时必须显式指定字符集,并且字符集只能是utf8mb4。创建数据库SQL举例:create database db1 default character set utf8mb4;。2.1.2 表结构【强制】表和列的名称必须控制在32个字符以内,表名只能使用字母、数字和下划线,一律小写。【强制】表名要求模块名强相关,如师资系统采用”sz”作为前缀,渠道系统采用”qd”作为前缀等。【强制】创建表时必须显式指定字符集为utf8mb4。【强制】创建表时必须显式指定表存储引擎类型,必须为InnoDB。因为Innodb表支持事务、行锁、宕机恢复、MVCC等关系型数据库重要特性,为业界使用最多的MySQL存储引擎。而这是其他大多数存储引擎不具备的。【强制】建表必须有comment【数仓要求】【强制】建表必须有行数据的创建时间字段create_time和最后更新时间字段update_time,同时该字段应使用入库时间,不要使用程序生成时间,避免数据库与服务器时间差异引起的数据问题【数仓要求】【建议】建表时关于主键:(1)强制要求主键为id,类型为int或bigint,且为auto_increment(2)标识表里每一行主体的字段不要设为主键,建议设为其他字段如user_id,order_id等,并建立unique key索引。因为如果设为主键且主键值为随机插入,则会导致innodb内部page分裂和大量随机I/O,性能下降。【建议】表中所有字段必须都是NOT NULL属性,业务可以根据需要定义DEFAULT值。因为使用NULL值会存在每一行都会占用额外存储空间、数据迁移容易出错、聚合函数计算结果偏差等问题。【建议】建议对表里的blob、text等大字段,垂直拆分到其他表里,仅在需要读这些对象的时候才去select。【建议】反范式设计:把经常需要join查询的字段,在其他表里冗余一份。如user_name属性在user_account,user_login_log等表里冗余一份,减少join查询。【强制】中间表用于保留中间结果集,名称必须以tmp_开头。备份表用于备份或抓取源表快照,名称必须以bak_开头。中间表和备份表定期清理。【强制】对于超过100W行的大表进行alter table,必须经过运维同学审核,并在业务低峰期执行。因为alter table会产生表锁,期间阻塞对于该表的所有写入,对于业务可能会产生极大影响。2.1.3 列数据类型优化【建议】表中的自增列(auto_increment属性),推荐使用bigint类型。因为无符号int存储范围为-2147483648~2147483647(大约21亿左右),溢出后会导致报错。【建议】业务中选择性很少的状态status、类型type等字段推荐使用tinytint或者smallint类型节省存储空间。【建议】业务中IP地址字段推荐使用int类型,不推荐用char(15)。因为int只占4字节,可以用如下函数相互转换,而char(15)占用至少15字节。一旦表数据行数到了1亿,那么要多用1.1G存储空间。 SQL:select inet_aton('192.168.2.12'); select inet_ntoa(3232236044); PHP: ip2long(‘192.168.2.12’); long2ip(3530427185);【建议】不推荐使用enum,set。 因为它们浪费空间,且枚举值写死了,变更不方便。推荐使用tinyint或smallint。【建议】不推荐使用blob,text等类型。它们都比较浪费硬盘和内存空间。在加载表数据时,会读取大字段到内存里从而浪费内存空间,影响系统性能。建议和PM、RD沟通,是否真的需要这么大字段。Innodb中当一行记录超过8098字节时,会将该记录中选取最长的一个字段将其768字节放在原始page里,该字段余下内容放在overflow-page里。不幸的是在compact行格式下,原始page和overflow-page都会加载。【建议】存储金钱的字段,建议用int,程序端乘以100和除以100进行存取。因为int占用4字节,而double占用8字节,空间浪费。【建议】文本数据尽量用varchar存储。因为varchar是变长存储,比char更省空间。一般建议用varchar类型,字符数不要超过2700。2.1.4 索引设计【强制】InnoDB表必须主键为id int/bigint auto_increment,且主键值禁止被更新。【建议】主键的名称以“pk_”开头,唯一键以“uk_”或“uq_”开头,普通索引以“idx_”开头,一律使用小写格式,以表名/字段的名称或缩写作为后缀。【强制】create_time和update_time必须加索引,用于数仓的数据同步,减少因为数仓同步对mysql数据库的压力【数仓要求】【强制】InnoDB存储引擎表,索引类型必须为BTREE【强制】单个索引中每个索引记录的长度不能超过64KB。【建议】单个表上的索引个数不能超过7个。【建议】在建立索引时,多考虑建立联合索引,并把区分度最高的字段放在最前面。如列userid的区分度可由select count(distinct userid)计算出来。【建议】在多表join的SQL里,保证被驱动表的连接列上有索引,这样join执行效率最高。【建议】建表或加索引时,保证表里互相不存在冗余索引。对于MySQL来说,如果表里已经存在key(a,b),则key(a)为冗余索引,需要删除。2.1.5 分库分表、分区表【强制】分区表的分区字段(partition-key)必须有索引,或者是组合索引的首列。【强制】单个分区表中的分区(包括子分区)个数不能超过1024。【强制】上线前RD或者运维同学必须指定分区表的创建、清理策略。【强制】访问分区表的SQL必须包含分区键。【建议】单个分区文件不超过2G,总大小不超过50G。建议总分区数不超过20个。【强制】对于分区表执行alter table操作,必须在业务低峰期执行。【强制】采用分库策略的,库的数量不能超过1024【强制】采用分表策略的,表的数量不能超过4096【建议】单个分表不超过500W行,ibd文件大小不超过2G,这样才能让数据分布式变得性能更佳。【建议】水平分表尽量用取模方式,日志、报表类数据建议采用日期进行分表。2.1.6 字符集【强制】数据库本身库、表、列所有字符集必须保持一致且为utf8mb4。【强制】前端程序字符集或者环境变量中的字符集,与数据库、表的字符集必须一致,统一为utf8。2.1.7 程序层DAO设计建议【建议】新的代码不要用model,推荐使用手动拼SQL+绑定变量传入参数的方式。因为model虽然可以使用面向对象的方式操作db,但是其使用不当很容易造成生成的SQL非常复杂,且model层自己做的强制类型转换性能较差,最终导致数据库性能下降。【建议】前端程序连接MySQL或者redis,必须要有连接超时和失败重连机制,且失败重试必须有间隔时间。【建议】前端程序报错里尽量能够提示MySQL或redis原生态的报错信息,便于排查错误。【建议】对于有连接池的前端程序,必须根据业务需要配置初始、最小、最大连接数,超时时间以及连接回收机制,否则会耗尽数据库连接资源,造成线上事故。【建议】对于log或history类型的表,随时间增长容易越来越大,因此上线前RD或者运维同学必须建立表数据清理或归档方案。【建议】在应用程序设计阶段,RD必须考虑并规避数据库中主从延迟对于业务的影响。尽量避免从库短时延迟(20秒以内)对业务造成影响,建议强制一致性的读开启事务走主库,或更新后过一段时间再去读从库。【建议】多个并发业务逻辑访问同一块数据(innodb表)时,会在数据库端产生行锁甚至表锁导致并发下降,因此建议更新类SQL尽量基于主键去更新。【建议】业务逻辑之间加锁顺序尽量保持一致,否则会导致死锁。【建议】对于单表读写比大于10:1的数据行或单个列,可以将热点数据放在缓存里(如mecache或redis),加快访问速度,降低MySQL压力。2.1.8 一个规范的建表语句示例一个较为规范的建表语句为:CREATE TABLE user ( id bigint(11) NOT NULL AUTO_INCREMENT, user_id bigint(11) NOT NULL COMMENT '用户id' username varchar(255) NOT NULL COMMENT '真实姓名', email varchar(255) NOT NULL COMMENT '用户邮箱', nickname varchar(255) NOT NULL COMMENT '昵称', avatar int(11) NOT NULL COMMENT '头像', birthday date NOT NULL COMMENT '生日', sex tinyint(4) DEFAULT '0' COMMENT '性别, 0为未知,1为男,2为女', short_introduce varchar(255) DEFAULT NULL COMMENT '一句话介绍自己,最多50个汉字', user_resume varchar(255) NOT NULL COMMENT '用户提交的简历存放地址', user_register_ip int NOT NULL COMMENT '用户注册时的源ip', create_time datetime NOT NULL COMMENT '用户记录创建的时间', update_time datetime NOT NULL COMMENT '用户资料修改的时间', user_review_status tinyint NOT NULL COMMENT '用户资料审核状态,1为通过,2为审核中,3为未通过,4为还未提交审核', PRIMARY KEY (id), UNIQUE KEY idx_user_id (user_id), KEY idx_username(username), KEY idx_create_time(create_time), KEY idx_update_time(update_time) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='网站用户基本信息';2.2 SQL编写2.2.1 DML语句【强制】SELECT语句必须指定具体字段名称,禁止写成。因为select 会将不该读的数据也从MySQL里读出来,造成网卡压力。且表字段一旦更新,但model层没有来得及更新的话,系统会报错。【强制】insert语句指定具体字段名称,不要写成insert into t1 values(…),道理同上。【建议】insert into…values(XX),(XX),(XX)…。这里XX的值不要超过5000个。值过多虽然上线很很快,但会引起主从同步延迟。【建议】SELECT语句不要使用UNION,推荐使用UNION ALL,并且UNION子句个数限制在5个以内。因为union all不需要去重,节省数据库资源,提高性能。【建议】in值列表限制在500以内。例如select… where userid in(….500个以内…),这么做是为了减少底层扫描,减轻数据库压力从而加速查询。【建议】事务里批量更新数据需要控制数量,进行必要的sleep,做到少量多次。【强制】事务涉及的表必须全部是innodb表。否则一旦失败不会全部回滚,且易造成主从库同步终端。【强制】写入和事务发往主库,只读SQL发往从库。【强制】除静态表或小表(100行以内),DML语句必须有where条件,且使用索引查找。【强制】生产环境禁止使用hint,如sql_no_cache,force index,ignore key,straight join等。因为hint是用来强制SQL按照某个执行计划来执行,但随着数据量变化我们无法保证自己当初的预判是正确的,因此我们要相信MySQL优化器!【强制】where条件里等号左右字段类型必须一致,否则无法利用索引。【强制】SELECT|UPDATE|DELETE|REPLACE要有WHERE子句,且WHERE子句的条件必需使用索引查找。【强制】生产数据库中强烈不推荐大表上发生全表扫描,但对于100行以下的静态表可以全表扫描。查询数据量不要超过表行数的25%,否则不会利用索引。【强制】WHERE 子句中禁止只使用全模糊的LIKE条件进行查找,必须有其他等值或范围查询条件,否则无法利用索引。【建议】索引列不要使用函数或表达式,否则无法利用索引。如where length(name)='Admin'或where user_id+2=10023。【建议】减少使用or语句,可将or语句优化为union,然后在各个where条件上建立索引。如where a=1 or b=2优化为where a=1… union …where b=2, key(a),key(b)。【建议】分页查询,当limit起点较高时,可先用过滤条件进行过滤。如select a,b,c from t1 limit 10000,20;优化为: select a,b,c from t1 where id>10000 limit 20;。2.2.2 多表连接【强制】禁止跨db的join语句。因为这样可以减少模块间耦合,为数据库拆分奠定坚实基础。【强制】禁止在业务的更新类SQL语句中使用join,比如update t1 join t2…。【建议】不建议使用子查询,建议将子查询SQL拆开结合程序多次查询,或使用join来代替子查询。【建议】线上环境,多表join不要超过3个表。【建议】多表连接查询推荐使用别名,且SELECT列表中要用别名引用字段,数据库.表格式,如select a from db1.table1 alias1 where …。【建议】在多表join中,尽量选取结果集较小的表作为驱动表,来join其他表。2.2.3 事务【建议】事务中INSERT|UPDATE|DELETE|REPLACE语句操作的行数控制在2000以内,以及WHERE子句中IN列表的传参个数控制在500以内。【建议】批量操作数据时,需要控制事务处理间隔时间,进行必要的sleep,一般建议值5-10秒。【建议】对于有auto_increment属性字段的表的插入操作,并发需要控制在200以内。【强制】程序设计必须考虑“数据库事务隔离级别”带来的影响,包括脏读、不可重复读和幻读。线上建议事务隔离级别为repeatable-read。【建议】事务里包含SQL不超过5个(支付业务除外)。因为过长的事务会导致锁数据较久,MySQL内部缓存、连接消耗过多等雪崩问题。【建议】事务里更新语句尽量基于主键或unique key,如update … where id=XX; 否则会产生间隙锁,内部扩大锁定范围,导致系统性能下降,产生死锁。【建议】尽量把一些典型外部调用移出事务,如调用webservice,访问文件存储等,从而避免事务过长。【建议】对于MySQL主从延迟严格敏感的select语句,请开启事务强制访问主库。2.2.4 排序和分组【建议】减少使用order by,和业务沟通能不排序就不排序,或将排序放到程序端去做。order by、group by、distinct这些语句较为耗费CPU,数据库的CPU资源是极其宝贵的。【建议】order by、group by、distinct这些SQL尽量利用索引直接检索出排序好的数据。如where a=1 order by b可以利用key(a,b)`。【建议】包含了order by、group by、distinct这些查询的语句,where条件过滤出来的结果集请保持在1000行以内,否则SQL会很慢。2.2.5 线上禁止使用的SQL语句【高危】禁用update|delete t1 … where a=XX limit XX; 这种带limit的更新语句。因为会导致主从不一致,导致数据错乱。建议加上order by PK。【高危】禁止使用关联子查询,如update t1 set … where name in(select name from user where…);效率极其低下。【高危】禁止一次add column多个字段,要拆成多条语句,逐条执行。【数仓要求】【强制】禁用procedure、function、trigger、views、event、外键约束。因为他们消耗数据库资源,降低数据库实例可扩展性。推荐都在程序端实现。【强制】禁用insert into …on duplicate key update…在高并发环境下,会造成主从不一致。【强制】禁止联表更新语句,如update t1,t2 where t1.id=t2.id建表强制要求create_time、update_time不能有业务含义,必须由数据库自己生成,业务时间用其他时间字段create_time、update_time 在建表时必须加索引建表必须要有字段comment,表comment必须要有逻辑删除字段 del_flag禁止物理删除数据,必须使用逻辑删除禁止一次add column多个字段,要拆成多条语句,逐条执行。
-
VSCode中的快捷使用 格式化代码:Alt + Shift + F 文档内搜索:Ctrl + F 搜索文件名:Ctrl + P 显示设置:Ctrl + , 选中所有相同项:Ctrl + D 增加Tab制表符:Tab 减少Tab制表符:Shift + Tab 注释:Ctrl + / 撤销:Ctrl + Z 复制多个光标:滚轮按住移动 复制内容:Ctrl + C 粘贴内容:Ctrl + V 剪切内容:Ctrl + X 复制粘贴内容:Alt + Shift + ↓快速生成代码:H$*5>{$} 乱数假文:lorem5 结合写法:H$*5>lorem$ ((h2[id="chapter$"]>{章节$})+p>lorem1000)*6 []内填写属性 +表示兄弟元素 ()为一个整体
-
git操作 1.查看本地分支:git branch2.查看远程分支:git branch -a3.将a分支合并到b分支内:确保当前已经切换到b分支,运行代码git merge a4.以master为基础新建分支feature/xxxx_xxxx_xxx:确保当前已经切换到master分支,运行代码git checkout -b feature/xxxx_xxxx_xxx5.删除本地分支:git branch -D feature/xxxx_xxxx_xxx1.将改动添加到暂存区:git add . 2.将暂存区内容创建一次提交记录:git commit -m "提交信息"3.查看分支commit记录:git log 4.查看分支所有操作记录:git reflog5.查看当前状态,判断下一步怎么操作:git status6.本地拉取远程更新:git pull7.将commit推送到远程仓库:git push合并commit操作1.合并多个commit提交记录为一个:git rebase -i HEAD~5 i进入编辑 只保留第一个commit,其余commit的pick都改成f esc退出 shift + :后wq回车更改保存2.第二种方法:git reset (实际commit_id,要合并到的目标commit_id的前一个commit_id)git add . git commit -m "提交信息"git push -f 强推git reset --hard 这是一种强制撤回修改用户名 --global参数表示全局修改git config --global user.name "你的用户名"查看用户名git config user.name修改最近一次commit备注git commit --amend 进入编辑后修改commit名或者一次性修改备注git commit --amend -m "你的备注"在远程创建新分支git push --set-upstream origin 你的分支名删除远程分支git push origin --delete 要删除的分支删除本地分支git branch -d 分支名修改分支名称git branch -m 分支名 修改后的分支名修改本地关联的远程仓库地址git remote -v (查看当前关联的远程仓库地址) git remote set-url origin 新的远程仓库地址 (修改远程仓库的URL) git remote rm origin (删除旧的远程仓库关联) git remote add origin 新的远程仓库地址 (添加新的远程仓库地址)撤销最近的一次commit 但保留工作区和暂存区代码git reset --soft HEAD~1撤销最近的一次commit 什么都不保留git reset --hard HEAD~1如果git rebase时出现冲突,手动解决冲突后显示正在变基中,可以git add .暂存修改,然后git rebase --continue继续变基git push --force 强推git push --force-with-lease 强推,但不会覆盖远程中别人提交的代码关于提交信息的格式,可以遵循以下命名规则: feat: 新特性,添加功能 fix: 修改 bug refactor: 代码重构 docs: 文档修改 style: 代码格式修改, 注意不是 css 修改 test: 测试用例修改 chore: 其他修改, 比如构建流程, 依赖管理新需求开发基本流程:1、在master分支git pull -r拉取最新代码,在master分支git checkout -b 新分支名,执行完毕后会自动切到新建的分支上,git push --set-upstream origin 新分支名在远程创建本分支。2、开发代码,完成一阶段开发后,git add .暂存修改,git commit -m "本次提交的备注"提交commit,git push推送到远程。这时可能遇到的问题:该需求需要在同一个分支开发,其他同学在远程提交了代码,此时需要同步远程代码,此情况详见一、更新远程代码。或者master分支有更新,需要同步master代码,此情况详见二、同步master代码到你的业务开发分支。3、发布测试环境,注意要切到最新的public分支,具体操作详见三、部署测试环境。因为public是公共分支,所以在合并的时候可能会有冲突,需要在本地解决冲突后再push到远程。4、业务开发完成,测试环境测试通过,可以发到线上了,具体操作详见四、发起上线请求。注意commit要合成一个,合并申请是申请到develop。5、需要注意的问题:(1)在开发前先使用git config user.name查看一下用户名,使用git config --global user.name "姓名拼音"改为名字的拼音,方便协作开发查看修改记录。(2)Windows操作系统设置git config --global core.autocrlf true去掉末尾行(3)如果是新业务开发,统一使用feat/或feature/前缀,分支名称和需求相关。(4)提交commit的备注要简明扼要,不要使用“初始化”、“第一次提交”等备注,特别是第一次commit,备注要和需求相关。如果备注不清楚,可以使用git commit --amend -m "你的备注"修改最近一次的commit备注。(5)如需回滚,可以使用git reflog查看详细操作,git reset 编码回滚。一、更新远程代码:1.当你本地有commit,但没有push到远程的时候,建议在当前需求分支feature/xxx_xxx使用git pull --rebase(简写:git pull -r) 进行拉取代码。可以避免产生(Merge branch 'feature/modify_document' into 'develop')记录。2.当你本地修改还没有commit提交,那么你可以将本地的修改先暂存起来,git stash,然后git pull拉取远程分支代码,最后再git stash pop取出你的修改,继续开发编码,完事后git add . ,git commit -m 'xx',git push。二、同步master代码到你的业务开发分支:1.请不要使用git merge master。咱们统一使用先切换到master分支,git pull更新本地master,然后切回自己分支,执行git rebase master。执行完命令后请观察vs-code编辑器左上角git源码管理图标如果有冲突,需要解决。解决后git add . , 然后shift + : ,wq 再按回车键。然后使用git rebase --continue (继续往下执行rebase), 如果特殊情况可使用git rebase --abort (撤销回到rebase之前原点),git rebase --skip (丢弃,引起冲突的commits会被丢弃,通常情况下请不要使用)三、部署测试环境切到最新的public分支,git pull -r 最新代码,git merge 你的分支,本地解决冲突,git push推到远程,再在jenkins上部署public分支程序。四、发起上线请求先在自己分支合并commit分支(git rebase -i HEAD~5,只保留第一个commit,其余commit的pick都改成f),再切到develop分支git pull -r获取最新代码,回到自己分支git rebase develop同步修改,本地解决冲突后,git push -f强推到自己分支,再在gitlab发起合并develop请求—— Merge requests—— New merge request—— 发线上变更公告—— 发线上变更审批