搜索到
22
篇与
的结果
-
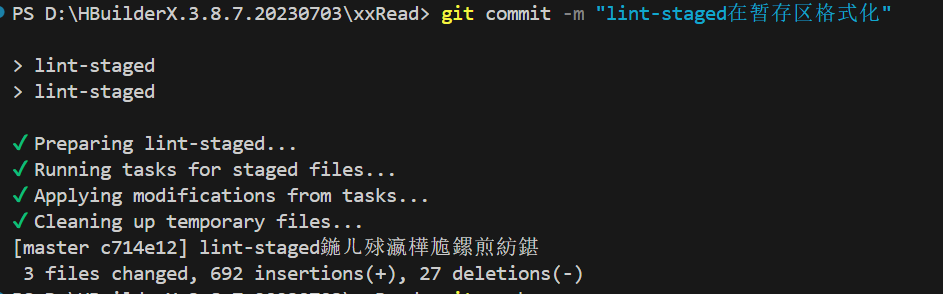
 vue项目commit自动格式化并提交 在 Vue 项目中,全局格式化(通常指的是代码格式化、样式格式化、数据格式化等)是一个重要的实践,它有助于维护代码的一致性和可读性,促进团队协作,减少因格式不一致导致的合并冲突,以及提高代码质量。先看效果:如果出现错误的commit做到commit的时候自动格式化,需要一下几个步骤:一 配置prettier安装Prettier: npm install --save-dev prettier 或者使用yarn yarn add --dev prettier配置Prettier:项目根目录新建配置文件,配置包括.prettierrc, .prettierrc.json, 或者在package.json内的prettier字段。例如创建一个.prettierrc文件,并设置一些基本规则:基本规则:{ "eslintIntegration": true, //设置为true时,Prettier会尝试避免与ESLint中的格式化规则冲突。这意呀着,如果ESLint和Prettier在格式化代码时有不同的规则,Prettier会尽量遵循ESLint的规则(前提是你已经安装了ESLint并配置了相应的规则)。 "stylelintIntegration": true, //类似于eslintIntegration,但它是针对CSS的。设置为true时,Prettier会尝试避免与Stylelint中的格式化规则冲突。这对于Vue项目中的<style>部分特别有用,但请注意,Prettier对CSS的支持可能不如Stylelint全面。 "tabWidth": 2, //设置缩进时使用的空格数。在你的配置中,它被设置为2,意味着每次缩进将使用两个空格。 "printWidth": 120, //指定代码行的最大长度。Prettier会尝试将代码格式化为不超过这个宽度的行。在你的配置中,它被设置为120个字符。 "singleQuote": true, //设置为true时,Prettier将使用单引号(')而不是双引号(")来包裹字符串。 "semi": false, //设置为true时,Prettier会在语句末尾添加分号。这是JavaScript中常见的做法,尽管ESLint等工具可能允许在某些情况下省略分号。 "arrowParens": "avoid", //控制箭头函数参数周围的括号。在你的配置中,它被设置为"avoid",这意味着Prettier会尽可能避免在箭头函数参数周围添加括号,除非这是必要的(例如,当参数是一个对象或数组时)。 "trailingComma": "none", //控制多行数组、对象字面量等末尾是否添加逗号。在你的配置中,它被设置为"none",意味着Prettier不会在末尾添加逗号。 "bracketSpacing": true //设置为true时,Prettier会在对象字面量、数组字面量等的大括号{}或方括号[]内部添加空格。这有助于提高代码的可读性。 }详细版本:{ "printWidth": 200, // 指定行的最大长度 "tabWidth": 4, // 指定缩进的空格数 "useTabs": true, // 是否使用制表符进行缩进,默认为 false "singleQuote": true, // 是否使用单引号,默认为 false "quoteProps": "as-needed", // 对象属性是否使用引号,默认为 "as-needed" "trailingComma": "none", // 是否使用尾随逗号(末尾的逗号),可以是 "none"、"es5"、"all" 三个选项 "bracketSpacing": true, // 对象字面量中的括号是否有空格,默认为 true "jsxBracketSameLine": false, // JSX 标签的右括号是否与前一行的末尾对齐,默认为 false "arrowParens": "always", // 箭头函数参数是否使用圆括号,默认为 "always" "rangeStart": 0, // 指定格式化的范围的起始位置 "requirePragma": false, // 是否需要在文件顶部添加特殊的注释才能进行格式化,默认为 false "insertPragma": false, // 是否在格式化后的文件顶部插入特殊的注释,默认为 false "proseWrap": "preserve", // 是否保留 markdown 文件中的换行符,默认为 "preserve" "htmlWhitespaceSensitivity": "ignore", // 指定 HTML 文件中空格敏感度的配置选项,可以是 "css"、"strict"、ignore "vueIndentScriptAndStyle": false, // 是否缩进 Vue 文件中的 <script> 和 <style> 标签,默认为 false "endOfLine": "auto", // 指定换行符的风格,可以是 "auto"、"lf"、"crlf"、"cr" 四个选项 "semi": true, // 行末是否添加分号,默认为 true "usePrettierrc": true, // 是否使用项目根目录下的 .prettierrc 文件,默认为 true "overrides": [ // 针对特定文件或文件类型的格式化配置 { "files": "*.json", // 匹配的文件或文件类型 "options": { "tabWidth": 4 // 针对该文件类型的配置选项 } }, { "files": "*.md", "options": { "printWidth": 100 } } ] }添加脚本到package.json: "scripts": { "lintfix": "prettier --write \"src/**/*.{js,ts,json,tsx,css,scss,vue,html,md}\"" },执行npm run lintfix即可进行格式化二 配置commit自动触发配置commit自动触发 1.安装huskynpm install husky --save-dev # 或者 yarn add husky --dev2.配置husky安装完husky后,需要通过npx husky-init(如果你使用npm)或yarn husky-init(如果你使用yarn)来初始化husky的配置。这个命令会添加一些必要的文件到你的项目中,并更新你的package.json以包含husky的配置。 npx husky-init初始化之后,会给我们自动创建一个.husky文件夹3.添加Git钩子在pre-commit后面加上commit时需要的操作这里是npm run lint-staged在package.json里也需要做配置:"husky": { "hooks": { "pre-commit": "npm run lint:prettier" } }三 配置lint-stagedlint-staged可以在commit之前对暂存区的内容做修改,有了它我们才能真正实现自动格式化并提交。有很多教程都只教到了第二步,只能做到commit时检测代码并格式化,格式化后还需要手动再执行一遍commit下载:npm install lint-staged --save-devpackage.json中配置: "scripts": { // 新增内容 "lint:prettier": "prettier --check .", "lintfix": "prettier --write --list-different .", "prepare": "husky install", "lint-staged": "lint-staged" }, "lint-staged": { "**/*.{js,vue}": [ "npm run lintfix" ] },做完这些配置即可实现commit自动修复代码格式并提交了。四 vscode保存时格式化在vscode的设置里面搜索formatOnSave,打上√。右键修改配置选择使用prettier即可五 参考文章解决:.prettierrc 配置完后,自动保存并没有格式化代码vue 项目commit自动格式化前端工程化-husky、eslint、prettier、lint-staged的使用【学不动系列】lint-staged 使用教程
vue项目commit自动格式化并提交 在 Vue 项目中,全局格式化(通常指的是代码格式化、样式格式化、数据格式化等)是一个重要的实践,它有助于维护代码的一致性和可读性,促进团队协作,减少因格式不一致导致的合并冲突,以及提高代码质量。先看效果:如果出现错误的commit做到commit的时候自动格式化,需要一下几个步骤:一 配置prettier安装Prettier: npm install --save-dev prettier 或者使用yarn yarn add --dev prettier配置Prettier:项目根目录新建配置文件,配置包括.prettierrc, .prettierrc.json, 或者在package.json内的prettier字段。例如创建一个.prettierrc文件,并设置一些基本规则:基本规则:{ "eslintIntegration": true, //设置为true时,Prettier会尝试避免与ESLint中的格式化规则冲突。这意呀着,如果ESLint和Prettier在格式化代码时有不同的规则,Prettier会尽量遵循ESLint的规则(前提是你已经安装了ESLint并配置了相应的规则)。 "stylelintIntegration": true, //类似于eslintIntegration,但它是针对CSS的。设置为true时,Prettier会尝试避免与Stylelint中的格式化规则冲突。这对于Vue项目中的<style>部分特别有用,但请注意,Prettier对CSS的支持可能不如Stylelint全面。 "tabWidth": 2, //设置缩进时使用的空格数。在你的配置中,它被设置为2,意味着每次缩进将使用两个空格。 "printWidth": 120, //指定代码行的最大长度。Prettier会尝试将代码格式化为不超过这个宽度的行。在你的配置中,它被设置为120个字符。 "singleQuote": true, //设置为true时,Prettier将使用单引号(')而不是双引号(")来包裹字符串。 "semi": false, //设置为true时,Prettier会在语句末尾添加分号。这是JavaScript中常见的做法,尽管ESLint等工具可能允许在某些情况下省略分号。 "arrowParens": "avoid", //控制箭头函数参数周围的括号。在你的配置中,它被设置为"avoid",这意味着Prettier会尽可能避免在箭头函数参数周围添加括号,除非这是必要的(例如,当参数是一个对象或数组时)。 "trailingComma": "none", //控制多行数组、对象字面量等末尾是否添加逗号。在你的配置中,它被设置为"none",意味着Prettier不会在末尾添加逗号。 "bracketSpacing": true //设置为true时,Prettier会在对象字面量、数组字面量等的大括号{}或方括号[]内部添加空格。这有助于提高代码的可读性。 }详细版本:{ "printWidth": 200, // 指定行的最大长度 "tabWidth": 4, // 指定缩进的空格数 "useTabs": true, // 是否使用制表符进行缩进,默认为 false "singleQuote": true, // 是否使用单引号,默认为 false "quoteProps": "as-needed", // 对象属性是否使用引号,默认为 "as-needed" "trailingComma": "none", // 是否使用尾随逗号(末尾的逗号),可以是 "none"、"es5"、"all" 三个选项 "bracketSpacing": true, // 对象字面量中的括号是否有空格,默认为 true "jsxBracketSameLine": false, // JSX 标签的右括号是否与前一行的末尾对齐,默认为 false "arrowParens": "always", // 箭头函数参数是否使用圆括号,默认为 "always" "rangeStart": 0, // 指定格式化的范围的起始位置 "requirePragma": false, // 是否需要在文件顶部添加特殊的注释才能进行格式化,默认为 false "insertPragma": false, // 是否在格式化后的文件顶部插入特殊的注释,默认为 false "proseWrap": "preserve", // 是否保留 markdown 文件中的换行符,默认为 "preserve" "htmlWhitespaceSensitivity": "ignore", // 指定 HTML 文件中空格敏感度的配置选项,可以是 "css"、"strict"、ignore "vueIndentScriptAndStyle": false, // 是否缩进 Vue 文件中的 <script> 和 <style> 标签,默认为 false "endOfLine": "auto", // 指定换行符的风格,可以是 "auto"、"lf"、"crlf"、"cr" 四个选项 "semi": true, // 行末是否添加分号,默认为 true "usePrettierrc": true, // 是否使用项目根目录下的 .prettierrc 文件,默认为 true "overrides": [ // 针对特定文件或文件类型的格式化配置 { "files": "*.json", // 匹配的文件或文件类型 "options": { "tabWidth": 4 // 针对该文件类型的配置选项 } }, { "files": "*.md", "options": { "printWidth": 100 } } ] }添加脚本到package.json: "scripts": { "lintfix": "prettier --write \"src/**/*.{js,ts,json,tsx,css,scss,vue,html,md}\"" },执行npm run lintfix即可进行格式化二 配置commit自动触发配置commit自动触发 1.安装huskynpm install husky --save-dev # 或者 yarn add husky --dev2.配置husky安装完husky后,需要通过npx husky-init(如果你使用npm)或yarn husky-init(如果你使用yarn)来初始化husky的配置。这个命令会添加一些必要的文件到你的项目中,并更新你的package.json以包含husky的配置。 npx husky-init初始化之后,会给我们自动创建一个.husky文件夹3.添加Git钩子在pre-commit后面加上commit时需要的操作这里是npm run lint-staged在package.json里也需要做配置:"husky": { "hooks": { "pre-commit": "npm run lint:prettier" } }三 配置lint-stagedlint-staged可以在commit之前对暂存区的内容做修改,有了它我们才能真正实现自动格式化并提交。有很多教程都只教到了第二步,只能做到commit时检测代码并格式化,格式化后还需要手动再执行一遍commit下载:npm install lint-staged --save-devpackage.json中配置: "scripts": { // 新增内容 "lint:prettier": "prettier --check .", "lintfix": "prettier --write --list-different .", "prepare": "husky install", "lint-staged": "lint-staged" }, "lint-staged": { "**/*.{js,vue}": [ "npm run lintfix" ] },做完这些配置即可实现commit自动修复代码格式并提交了。四 vscode保存时格式化在vscode的设置里面搜索formatOnSave,打上√。右键修改配置选择使用prettier即可五 参考文章解决:.prettierrc 配置完后,自动保存并没有格式化代码vue 项目commit自动格式化前端工程化-husky、eslint、prettier、lint-staged的使用【学不动系列】lint-staged 使用教程 -
js工具函数大全 效验相关 /** * 手机号码 * @param val 当前值字符串 * @returns 返回 true: 手机号码正确 */ export function verifyPhone(val) { // false: 手机号码不正确 // if ( // !/^((12[0-9])|(13[0-9])|(14[5|7])|(15([0-3]|[5-9]))|(16([0-3]|[5-9]))|(17([0-3]|[5-9]))|(18[0,5-9]))\d{8}$/.test( // val // ) // ) { if (!/^1[3-9]\d{9}$/.test(val)) { return false } else { return true } } /** * 国内电话号码 * @param val 当前值字符串 * @returns 返回 true: 国内电话号码正确 */ export function verifyTelPhone(val) { // false: 国内电话号码不正确 if (!/\d{3}-\d{8}|\d{4}-\d{7}/.test(val)) return false // true: 国内电话号码正确 else return true } /** * 密码 (以字母开头,长度在6~16之间,只能包含字母、数字和下划线) * @param val 当前值字符串 * @returns 返回 true: 密码正确 */ export function verifyPassword(val) { // false: 密码不正确 if (!/^[a-zA-Z]\w{5,15}$/.test(val)) return false // true: 密码正确 else return true } /** * 强密码 (字母+数字+特殊字符,长度在6-16之间) * @param val 当前值字符串 * @returns 返回 true: 强密码正确 */ export function verifyPasswordPowerful(val) { // false: 强密码不正确 if ( !/^(?![a-zA-z]+$)(?!\d+$)(?![!@#$%^&\.*]+$)(?![a-zA-z\d]+$)(?![a-zA-z!@#$%^&\.*]+$)(?![\d!@#$%^&\.*]+$)[a-zA-Z\d!@#$%^&\.*]{6,16}$/.test( val ) ) { return false } else { return true } } /** * 密码强度 * @param val 当前值字符串 * @description 弱:纯数字,纯字母,纯特殊字符 * @description 中:字母+数字,字母+特殊字符,数字+特殊字符 * @description 强:字母+数字+特殊字符 * @returns 返回处理后的字符串:弱、中、强 */ export function verifyPasswordStrength(val) { let v = '' // 弱:纯数字,纯字母,纯特殊字符 if (/^(?:\d+|[a-zA-Z]+|[!@#$%^&\.*]+){6,16}$/.test(val)) v = '弱' // 中:字母+数字,字母+特殊字符,数字+特殊字符 if (/^(?![a-zA-z]+$)(?!\d+$)(?![!@#$%^&\.*]+$)[a-zA-Z\d!@#$%^&\.*]{6,16}$/.test(val)) v = '中' // 强:字母+数字+特殊字符 if ( /^(?![a-zA-z]+$)(?!\d+$)(?![!@#$%^&\.*]+$)(?![a-zA-z\d]+$)(?![a-zA-z!@#$%^&\.*]+$)(?![\d!@#$%^&\.*]+$)[a-zA-Z\d!@#$%^&\.*]{6,16}$/.test( val ) ) { v = '强' } // 返回结果 return v } /** * IP地址 * @param val 当前值字符串 * @returns 返回 true: IP地址正确 */ export function verifyIPAddress(val) { // false: IP地址不正确 if ( !/^(\d{1,2}|1\d\d|2[0-4]\d|25[0-5])\.(\d{1,2}|1\d\d|2[0-4]\d|25[0-5])\.(\d{1,2}|1\d\d|2[0-4]\d|25[0-5])\.(\d{1,2}|1\d\d|2[0-4]\d|25[0-5])$/.test( val ) ) { return false } else { return true } } /** * 邮箱 * @param val 当前值字符串 * @returns 返回 true: 邮箱正确 */ export function verifyEmail(val) { // false: 邮箱不正确 if ( !/^(([^<>()\[\]\\.,;:\s@"]+(\.[^<>()\[\]\\.,;:\s@"]+)*)|(".+"))@((\[[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\])|(([a-zA-Z\-0-9]+\.)+[a-zA-Z]{2,}))$/.test( val ) ) { return false } else { return true } } /** * 身份证 * @param val 当前值字符串 * @returns 返回 true: 身份证正确 */ export function verifyIdCard(val) { // false: 身份证不正确 /** * 表达式解释 * ^[1-9]\d{5}:身份证号码的前6位是行政区划代码,以1-9的数字开头,后面跟着5个数字。 * (18|19|20)\d{2}:接下来的4位是年份,可以是18、19或20开头的年份。 * (0[1-9]|1[0-2]):接下来的2位是月份,01到12之间的数字。 * (0[1-9]|[12]\d|3[01]):接下来的2位是日期,可以是01到31之间的数字。 * \d{3}:接下来的3位是顺序码,通常是随机生成的数字。 * [\dxX]$:最后一位是校验位,可以是数字、小写字母x或大写字母X,用于校验身份证号码的合法性。 */ if (!/^[1-9]\d{5}(18|19|20)\d{2}(0[1-9]|1[0-2])(0[1-9]|[12]\d|3[01])\d{3}[\dxX]$/.test(val)) { return false } else { return true } } /** * 姓名 * @param val 当前值字符串 * @returns 返回 true: 姓名正确 */ export function verifyFullName(val) { // false: 姓名不正确 if (!/^[\u4e00-\u9fa5]{1,6}(·[\u4e00-\u9fa5]{1,6}){0,2}$/.test(val)) return false // true: 姓名正确 else return true } /** * 邮政编码 * @param val 当前值字符串 * @returns 返回 true: 邮政编码正确 */ export function verifyPostalCode(val) { // false: 邮政编码不正确 if (!/^[1-9][0-9]{5}$/.test(val)) return false // true: 邮政编码正确 else return true } /** * url 处理 * @param val 当前值字符串 * @returns 返回 true: url 正确 */ export function verifyUrl(val) { // false: url不正确 if ( !/^(?:(?:(?:https?|ftp):)?\/\/)(?:\S+(?::\S*)?@)?(?:(?!(?:10|127)(?:\.\d{1,3}){3})(?!(?:169\.254|192\.168)(?:\.\d{1,3}){2})(?!172\.(?:1[6-9]|2\d|3[0-1])(?:\.\d{1,3}){2})(?:[1-9]\d?|1\d\d|2[01]\d|22[0-3])(?:\.(?:1?\d{1,2}|2[0-4]\d|25[0-5])){2}(?:\.(?:[1-9]\d?|1\d\d|2[0-4]\d|25[0-4]))|(?:(?:[a-z\u00a1-\uffff0-9]-*)*[a-z\u00a1-\uffff0-9]+)(?:\.(?:[a-z\u00a1-\uffff0-9]-*)*[a-z\u00a1-\uffff0-9]+)*(?:\.(?:[a-z\u00a1-\uffff]{2,})).?)(?::\d{2,5})?(?:[/?#]\S*)?$/i.test( val ) ) { return false } else { return true } } /** * 验证码位数校验 * @param {*} val 验证码 * @param {*} num 验证码位数 */ export function verifyCode(val) { const reg = new RegExp(/^[0-9]\d{5}$/) if (!reg.test(val)) return false else return true } /** * 验证百分比(不可以小数) * @param val 当前值字符串 * @returns 返回处理后的字符串 */ export function verifyNumberPercentage(val) { // 匹配空格 let v = val.replace(/(^\s*)|(\s*$)/g, '') // 只能是数字和小数点,不能是其他输入 v = v.replace(/[^\d]/g, '') // 不能以0开始 v = v.replace(/^0/g, '') // 数字超过100,赋值成最大值100 v = v.replace(/^[1-9]\d\d{1,3}$/, '100') // 返回结果 return v } /** * 验证百分比(可以小数) * @param val 当前值字符串 * @returns 返回处理后的字符串 */ export function verifyNumberPercentageFloat(val) { let v = verifyNumberIntegerAndFloat(val) // 数字超过100,赋值成最大值100 v = v.replace(/^[1-9]\d\d{1,3}$/, '100') // 超过100之后不给再输入值 v = v.replace(/^100\.$/, '100') // 返回结果 return v } /** * 小数或整数(不可以负数) * @param val 当前值字符串 * @returns 返回处理后的字符串 */ export function verifyNumberIntegerAndFloat(val) { // 匹配空格 let v = val.replace(/(^\s*)|(\s*$)/g, '') // 只能是数字和小数点,不能是其他输入 v = v.replace(/[^\d.]/g, '') // 以0开始只能输入一个 v = v.replace(/^0{2}$/g, '0') // 保证第一位只能是数字,不能是点 v = v.replace(/^\./g, '') // 小数只能出现1位 v = v.replace('.', '$#$').replace(/\./g, '').replace('$#$', '.') // 小数点后面保留2位 v = v.replace(/^(\-)*(\d+)\.(\d\d).*$/, '$1$2.$3') // 返回结果 return v } /** * 检测是否是Number类型,排除NaN */ export function isNumber(number) { return /^[+-]?(0|([1-9]\d*))(\.\d+)?$/g.test(number) } /** * 正整数验证 * @param val 当前值字符串 * @returns 返回处理后的字符串 */ export function verifiyNumberInteger(val) { // 匹配空格 let v = val.replace(/(^\s*)|(\s*$)/g, '') // 去掉 '.' , 防止贴贴的时候出现问题 如 0.1.12.12 v = v.replace(/[\.]*/g, '') // 去掉以 0 开始后面的数, 防止贴贴的时候出现问题 如 00121323 v = v.replace(/(^0[\d]*)$/g, '0') // 首位是0,只能出现一次 v = v.replace(/^0\d$/g, '0') // 只匹配数字 v = v.replace(/[^\d]/g, '') // 返回结果 return v } /** * 去掉中文及空格 * @param val 当前值字符串 * @returns 返回处理后的字符串 */ export function verifyCnAndSpace(val) { // 匹配中文与空格 let v = val.replace(/[\u4e00-\u9fa5\s]+/g, '') // 匹配空格 v = v.replace(/(^\s*)|(\s*$)/g, '') // 返回结果 return v } /** * 去掉英文及空格 * @param val 当前值字符串 * @returns 返回处理后的字符串 */ export function verifyEnAndSpace(val) { // 匹配英文与空格 let v = val.replace(/[a-zA-Z]+/g, '') // 匹配空格 v = v.replace(/(^\s*)|(\s*$)/g, '') // 返回结果 return v } /** * 禁止输入空格 * @param val 当前值字符串 * @returns 返回处理后的字符串 */ export function verifyAndSpace(val) { // 匹配空格 const v = val.replace(/(^\s*)|(\s*$)/g, '') // 返回结果 return v } 文件相关export const downloadFile = (url = '', fileName = '未知文件', cb) => { const a = document.createElement('a') a.style.display = 'none' a.setAttribute('target', '_blank') /* * download的属性是HTML5新增的属性 * href属性的地址必须是非跨域的地址,如果引用的是第三方的网站或者说是前后端分离的项目(调用后台的接口),这时download就会不起作用。 * 此时,如果是下载浏览器无法解析的文件,例如.exe,.xlsx..那么浏览器会自动下载,但是如果使用浏览器可以解析的文件,比如.txt,.png,.pdf....浏览器就会采取预览模式 * 所以,对于.txt,.png,.pdf等的预览功能我们就可以直接不设置download属性(前提是后端响应头的Content-Type: application/octet-stream,如果为application/pdf浏览器则会判断文件为 pdf ,自动执行预览的策略) */ fileName && a.setAttribute('download', fileName) a.href = url document.body.appendChild(a) a.click() document.body.removeChild(a) cb && cb() } export const downloadBlob = (data, fileName = '未知文件.xlsx', type) => { const blob = new Blob([data], { type }) // 处理文档流 const a = document.createElement('a') // 创建a标签 a.download = fileName.replace(new RegExp('"', 'g'), '') a.style.display = 'none' a.href = URL.createObjectURL(blob) // 创建blob地址 document.body.appendChild(a) // 将a标签添加到body中 a.click() URL.revokeObjectURL(a.href) // 释放URL对象 document.body.removeChild(a) // 从body中移除a标签 } /** * 文件大小转换对应单位大小 * @param size 文件大小,字节(B)单位 * @returns 返回 string */ export function transformFileSizeUnit(size) { if (!size) return '' let sizestr = '' if (size < 0.1 * 1024) { // 如果小于0.1KB转化成B sizestr = size.toFixed(2) + 'B' } else if (size < 1 * 1024 * 1024) { // 如果小于1MB转化成KB sizestr = (size / 1024).toFixed(2) + 'KB' } else if (size < 1 * 1024 * 1024 * 1024) { // 如果小于1GB转化成MB sizestr = (size / (1024 * 1024)).toFixed(2) + 'MB' } else { // 其他转化成GB sizestr = (size / (1024 * 1024 * 1024)).toFixed(2) + 'GB' } return sizestr.replace('.00', '') } /** * @description: 将 BASE64 转换文件 * @param {*} * @return {*} */ export const dataURLtoFile = (dataurl, filename) => { const arr = dataurl.split(','); const mime = arr[0].match(/:(.*?);/)[1]; if (!filename) filename = `${Date.parse(new Date())}.jpg`; const bstr = window.atob(arr[1]); let n = bstr.length; const u8arr = new Uint8Array(n); while (n--) { u8arr[n] = bstr.charCodeAt(n); } return new File([u8arr], filename, { type: mime }); }工具函数 /** * 金额用 `,` 区分开 * @param val 当前值字符串 * @returns 返回处理后的字符串 */ export function verifyNumberComma(val) { // 调用小数或整数(不可以负数)方法 let v = verifyNumberIntegerAndFloat(val) // 字符串转成数组 v = v.toString().split('.') // \B 匹配非单词边界,两边都是单词字符或者两边都是非单词字符 v[0] = v[0].replace(/\B(?=(\d{3})+(?!\d))/g, ',') // 数组转字符串 v = v.join('.') // 返回结果 return v } /** * 匹配文字变色(搜索时) * @param val 当前值字符串 * @param text 要处理的字符串值 * @param color 搜索到时字体高亮颜色 * @returns 返回处理后的字符串 */ export function verifyTextColor(val, text = '', color = 'red') { // 返回内容,添加颜色 const v = text.replace(new RegExp(val, 'gi'), `<span style='color: ${color}'>${val}</span>`) // 返回结果 return v } /** * 数字转中文大写 * @param val 当前值字符串 * @param unit 默认:仟佰拾亿仟佰拾万仟佰拾元角分 * @returns 返回处理后的字符串 */ export function verifyNumberCnUppercase(val, unit = '仟佰拾亿仟佰拾万仟佰拾元角分', v = '') { // 当前内容字符串添加 2个0,为什么?? val += '00' // 返回某个指定的字符串值在字符串中首次出现的位置,没有出现,则该方法返回 -1 const lookup = val.indexOf('.') // substring:不包含结束下标内容,substr:包含结束下标内容 if (lookup >= 0) val = val.substring(0, lookup) + val.substr(lookup + 1, 2) // 根据内容 val 的长度,截取返回对应大写 unit = unit.substr(unit.length - val.length) // 循环截取拼接大写 for (let i = 0; i < val.length; i++) { v += '零壹贰叁肆伍陆柒捌玖'.substr(val.substr(i, 1), 1) + unit.substr(i, 1) } // 正则处理 v = v .replace(/零角零分$/, '整') .replace(/零[仟佰拾]/g, '零') .replace(/零{2,}/g, '零') .replace(/零([亿|万])/g, '$1') .replace(/零+元/, '元') .replace(/亿零{0,3}万/, '亿') .replace(/^元/, '零元') // 返回结果 return v } /** * 多维数组去重(包含对象) * @param {Array} arrayData // 需要去重的数组 * @param {String} key // 根据属性进行去重 */ export const multiArrayDedup = (arrayData = [], key = '') => { const hashKey = {} const result = [ ...new Set( arrayData.reduce((item, next) => { return item.concat(next) }, []) ) ].reduce((item, next) => { if (next[key]) { // eslint-disable-next-line no-unused-expressions hashKey[next[key]] ? '' : (hashKey[next[key]] = true && item.push(next)) } else { item.push(next) } return item }, []) return result } /** * 对象数组去重 * @param {Array} arrayData // 需要去重的数组 * @param {String} key // 根据属性进行去重 */ export const objectArrayDedup = (arrayData = [], key = '') => { const hash = {} // 缓存对象数组里的某一个属性 const result = arrayData.reduce((item, next, index, data) => { // eslint-disable-next-line no-unused-expressions hash[next[key]] ? '' : (hash[next[key]] = true && item.push(next)) return item }, []) return result } /** * 普通数组去重 * @param {Array} arrayData // 需要去重的数组 */ export const normalArrayDedup = (arrayData = []) => { const result = arrayData.reduce((item, next) => { item.indexOf(next) === -1 && item.push(next) return item }, []) return result } /** * 判断是否文本溢出 * @param e 事件对象 * @returns 返回true为未溢出 false溢出 */ export const isBeyond = e => { const ev = window.event || e const textRange = el => { const textContent = el const targetW = textContent.getBoundingClientRect().width const range = document.createRange() range.setStart(textContent, 0) range.setEnd(textContent, textContent.childNodes.length) const rangeWidth = range.getBoundingClientRect().width return rangeWidth > targetW } return !textRange(ev.target) } // 获取字数 中文单字算一个字数 英文按空格算一个字数 // 例如:a app 两个字数 // a app 很好 四个字数 export const tokenizeLens = text => { // 英文分词:按空格分词 const englishTokens = text.split(' ') // 中文分词:按单个字符分词 const chineseTokens = text.split('').filter(char => /[\u4e00-\u9fff]/.test(char)) // 合并英文字符和中文单字 const tokens = englishTokens.concat(chineseTokens) // 返回词汇总数 return tokens.length }
-
webRTC与webSocket接入智谱视频通话API避坑指南 先看效果:智谱新上线的音视频通话大模型拥有理解音频和画面的能力,接入该api,需要使用webSocket协议不断传输音频和视频的base64编码。WebRTC(Web Real-Time Communication)是一个支持网页浏览器进行实时语音对话或视频对话的技术,webRTC最强大的功能是无需服务器,可以实现浏览器端对端的音视频通话,这里只使用了webRTC实现视频画面显示。这里就详细说一下从开发到跑起这个demo踩的一些不得不说的血泪坑。一技术栈使用vue2,webRTC自然就选用了vue-webRTC,npm地址:https://www.npmjs.com/package/vue-webrtc/v/2.0.0?activeTab=readme通过看它的readme文档发现,最新版是3.0.1,从3.0.0开始支持vue3,vue2使用的是2.0.0版本。跑vue-webRTC这个示例没有出现问题,但是上线的时候却发现一直报错:Permissions policy violation: camera is not allowed in this document.网上有关这些的文档都是说没有授权导致,在这里查资料卡了很久。线上使用的也是https协议,也授权了权限,调试很多次一直报错,终于在一篇文档里发现了问题: 【Web安全】Permissions Policy(权限策略)详解 不知道是谁给线上环境的响应头里设置了不允许使用麦克风和摄像头,也是吐血了。这里需要从Nginx修改配置,于是换了一个线上环境,成功解决。二智谱接入模型需要使用webSocket协议,这很简单,使用原生js new WebSocket(url)即可,提供了.send()方法发送数据,.onopen方法监听建立连接成功 .onmessage方法监听服务器返回。部分代码如下: this.ws = new WebSocket(this.socketURL + `?Authorization=${APIKey}`) this.ws.onopen = () => { console.log('WebSocket 连接已打开') } this.ws.onmessage = event => { let data = JSON.parse(event.data) console.log('收到服务器消息:', data) } // 发送消息 this.ws.send(JSON.stringify(message))但是接入的时候需要传入apiKey进行鉴权,api文档里写的是将key放在Header头里面,这完全就没有考虑浏览器调用情况!浏览器端对写入header头很严格,而且这也不是简单的get post请求,可以用axios工具设置请求头。所以当时有两种方法,1、找一个可以支持websocket协议写入请求头的库 2、使用@fortaine/fetch-event-source发送fetch请求,fetch是websocket的替代方案,可以解决传复杂参数问题。因为有一个已经封装好了的可以用fetch的库,所以当时选择通过fetch协议调用。通过一番操作以后,发post请求报405 发get请求报400,调试到这里真是吐血了!!用文档给的java代码调用就没有问题,这个文档根本就没有考虑浏览器方案。服务器端只支持websocket协议,而websocket或eventsource是get请求,带参只能跟在url地址后面。所以发post会报405请求方法不对,后端又只从请求头里拿鉴权信息,发get带过去的它都不认。经过一番协商,后端改了鉴权方法,从url地址里拿key信息,这下直接用原生webSocket协议都行了。调试半天,后端改一下协议十分钟搞定。三搞定传输以后,剩下的就比较简单了,从音视频流里获取视频和音频数据,再转成base64编码,直接发送即可。特别感谢:https://github.com/2fps/recorder作者整理的关于音频的资料很详细。请求获取音视频流: // 获得音视频数据流 getUserMedia() { if (navigator.mediaDevices && navigator.mediaDevices.getUserMedia) { navigator.mediaDevices .getUserMedia({ audio: true, // 设置为 true 以请求音频流 video: true }) .then(stream => { // 拿到音视频数据流 this.activeStream = stream // 包含视频&&音频 this.videoStream = new MediaStream(stream) // 创建只包含视频轨道的 MediaStream // this.videoStream = new MediaStream() // this.activeStream.getVideoTracks().forEach(track => this.videoStream.addTrack(track)) // 创建只包含音频轨道的 MediaStream this.audioStream = new MediaStream() this.activeStream.getAudioTracks().forEach(track => this.audioStream.addTrack(track)) // 获得音频数据流 this.getAudioBlob() this.getVideoBlob() }) .catch(err => { console.error('获取用户媒体流失败:', err) }) } else { alert('你的浏览器不支持 getUserMedia') } },获得音频流数据 // 获得音频数据流 getAudioBlob() { // 获得pcm格式的音频数据 // 创建 AudioContext const audioContext = new (window.AudioContext || window.webkitAudioContext)() // 创建 MediaStreamSource const source = audioContext.createMediaStreamSource(this.audioStream) // 创建录音节点,指定缓冲区大小和处理音频的输入输出通道数 const scriptProcessor = audioContext.createScriptProcessor(4096, 1, 1) // 将音频输入源连接到录音节点,并将录音节点连接到音频上下文的输出 source.connect(scriptProcessor) scriptProcessor.connect(audioContext.destination) // 存储 scriptProcessor 和 audioContext 以便之后可以断开连接 this.scriptProcessor = scriptProcessor this.audioContext = audioContext // 当音频数据可用时执行的回调函数 scriptProcessor.onaudioprocess = audioProcessingEvent => { const inputBuffer = audioProcessingEvent.inputBuffer // 获取第一个(也是唯一一个)输入通道的 Float32Array 数据 leftChannelData 就是 PCM 数据 const leftChannelData = inputBuffer.getChannelData(0) this.inputAudioData.push(new Float32Array(leftChannelData)) this.audioSize += leftChannelData.length } },获得视频流数据// 获得视频数据流 getVideoBlob() { // 设置 MediaRecorder 选项 const videoOptions = { mimeType: 'video/webm;codecs=H264' } // 创建视频 MediaRecorder this.videoMediaRecorder = new MediaRecorder(this.videoStream, videoOptions) // 当stop时触发 this.videoMediaRecorder.ondataavailable = event => { if (event.data && event.data.size > 0) { const data = event.data // 获得音视频的Blob对象 const blobDate = this.getBlob(data) if (this.control.vad_config.server_vad) { // 获得base64数据 this.getBase64(blobDate.videoBlob, blobDate.audioBlob) } else { // 存储blob对象 等待手动发送 this.audioBlobs.push(blobDate.audioBlob) this.videoBlobs.push(blobDate.videoBlob) } } } // 当录制停止时触发 this.videoMediaRecorder.onstop = () => { // 开启vad检测时 触发开启事件 if (this.control.vad_config.server_vad) { this.videoMediaRecorder.start() } } },在这里也要说一点this.videoMediaRecorder.start()开启的时候可以加参数 即多少ms触发一次ondataavailable回调,但是这样在ondataavailable里面拿到的数据只有第一次有头部,后面触发获得的没有头部,需要把所有数据段的拼接起来才能组成完整的视频片段。所有这里采用加一个定时器定时触发stop,stop也会触发ondataavailable,并且监听stop的触发,stop停止时就开启,这样拿到的是完整的视频片段。获得音视频数据后,下面再转成base64即可,下面是互相转换的函数: /** * 将Blob对象转换为数组。 * * @param {Blob} blob - 要转换的Blob对象。 * @returns {Promise<Uint8Array>} 返回一个Promise,该Promise解析为一个包含二进制数据的Uint8Array数组。 */ export function blobToBinaryArray(blob) { return new Promise((resolve, reject) => { const reader = new FileReader() reader.onload = function () { const arrayBuffer = reader.result const bytes = new Uint8Array(arrayBuffer) resolve(bytes) } reader.onerror = function (error) { reject(error) } reader.readAsArrayBuffer(blob) }) } /** * 将Blob对象转换为Base64编码的字符串。 * @param {Blob} blob - 要转换的Blob对象。 * @returns {Promise<string>} 返回一个Promise,解析为Base64编码的字符串。 */ export function blobToBase64(blob) { return new Promise((resolve, reject) => { const reader = new FileReader() reader.onloadend = function () { const base64String = reader.result.split(',')[1] resolve(base64String) } reader.onerror = reject reader.readAsDataURL(blob) }) } /** * 将Base64编码的字符串转换为Blob对象。 * @param {string} base64 - 需要转换的Base64编码字符串 * @param {string} mimeType - Blob对象的MIME类型,例如'image/jpeg'或'image/png'。 * @returns {Blob} 返回一个Blob对象 */ export function base64ToBlob(base64, mimeType) { // 分割Base64字符串以获取数据部分,通常Base64字符串以"data:image/...,"开头 const byteString = atob(base64) // 创建一个ArrayBuffer,其大小与解码后的字符串长度相同 const ab = new ArrayBuffer(byteString.length) // 创建一个Uint8Array视图,将ArrayBuffer的内容初始化为8位无符号整数值 const ia = new Uint8Array(ab) // 遍历解码后的字符串,并将每个字符的Unicode编码存入Uint8Array数组 for (let i = 0; i < byteString.length; i++) { ia[i] = byteString.charCodeAt(i) } // 使用ArrayBuffer和MIME类型创建Blob对象 const blob = new Blob([ab], { type: mimeType }) // 返回Blob对象 return blob } /** * 将Base64编码的字符串转换为ArrayBuffer。 * @param {string} base64 - 需要转换的Base64编码字符串。 * @returns {ArrayBuffer} 返回一个ArrayBuffer对象,它包含了从Base64字符串转换而来的字节数据。 */ export function base64ToArrayBuffer(base64) { const binaryString = window.atob(base64) // 使用window.atob()方法将Base64编码的字符串解码成二进制字符串 const len = binaryString.length // 获取二进制字符串的长度 const bytes = new Uint8Array(len) // 创建一个Uint8Array数组,用于存储转换后的字节数据 for (let i = 0; i < len; i++) { // 遍历二进制字符串的每个字符 bytes[i] = binaryString.charCodeAt(i) // 将每个字符的charCodeAt值(即字符的Unicode编码)存储到Uint8Array数组中 } return bytes.buffer // 返回Uint8Array数组的buffer属性,它是一个ArrayBuffer对象 } 四该api会有两种返回方式:1、返回文本 2、默认返回音频这样就比较难受了,不能同时展示,而且模型返回的音频是带感情的,还不能简单的文字转音频。现在常见的音频转文本方案都是调用外部api,或者在浏览器端运行转文本模型(这个试了一下它们的样例,不仅要翻墙,一百多兆的模型转的文本错字也很多)最后放弃了,写了一个文本和语音播放,返回文本就展示文本,返回语音就展示语音。语音返回的是pcm或wav格式的base64字符串,将base64字符串转成blob对象,创建一个资源url,写进audio.src里播放即可,这里比较简单,详见代码: // 播放音频流数据 outAudios(serverMessagesIndex) { let nextAudioMessage = this.serverMessages[serverMessagesIndex] // 设置播放动画 for (let i = 0; i < this.serverMessages.length; i++) { this.serverMessages[i].voicePlay = false } this.serverMessages[serverMessagesIndex].voicePlay = true console.log(nextAudioMessage) if (this.serverMessages.length < 1) { return } let audioContent = nextAudioMessage.audioContent let audioBase64 = '' let wavBlobs = [] for (let i = 0; i < audioContent.length; i++) { // 服务端返回的是base64字符串 audioBase64 = audioContent[i] // wav Blob对象 const wavBlob = base64ToBlob(audioBase64, 'audio/mav') wavBlobs.push(wavBlob) } // download(wavBlobs[0], 'wav') // 播放音频 this.playNextAudio(wavBlobs, 0, serverMessagesIndex) }, // 播放音频的函数 playNextAudio(wavBlobs, currentAudioIndex, serverMessagesIndex) { if (currentAudioIndex < wavBlobs.length) { // 创建音频URL let audioSrc = URL.createObjectURL( // new Blob([wavBlobs[currentAudioIndex]], { type: 'audio/wav' }) wavBlobs[currentAudioIndex] ) // 设置音频源并播放 this.audioElement.src = audioSrc this.audioElement.play() // 当音频播放完毕 this.audioElement.onended = () => { console.log(audioSrc, '音频播放完毕:') if ( !isNaN(this.audioElement.duration) && this.serverMessages[serverMessagesIndex].isDuration ) { // 加入长度 this.serverMessages[serverMessagesIndex].audioDuration += this.audioElement.duration this.serverMessages[serverMessagesIndex].audioDuration = +this.serverMessages[serverMessagesIndex].audioDuration.toFixed(0) } // 释放创建的URL对象 URL.revokeObjectURL(audioSrc) // 更新索引以播放下一个音频 currentAudioIndex++ // 播放下一个音频 this.playNextAudio(wavBlobs, currentAudioIndex, serverMessagesIndex) } } else { console.log('所有音频播放完毕') this.serverMessages[serverMessagesIndex].voicePlay = false this.serverMessages[serverMessagesIndex].isDuration = false return -1 } },大功告成!五 参考资料WebRTC本地实现 - WebRTC通信实现(Web端) 【Web安全】Permissions Policy(权限策略)详解 实时音视频WebRTC常见问题汇总 Vue使用js-audio-recorder实现录制,播放与下载音频功能 WebRTC 从实战到未来!
-
详谈JavaScript发展史 JavaScript发展史 1995年Navigator公司为了可以控制浏览器行为,将某些不宜在服务端完成的操作放到客户端完成,开发了可以嵌入网页的脚本语言JavaScript,并在1996年将JavaScript正式内置在了他们的产品Navigator 2.0 浏览器中。同年,它的竞争对手微软公司,copy了JavaScript,改名叫做JScript,并搭载在IE3.0浏览器中。 Navigator为了抵制微软,规范JavaScript语言,决定将JavaScript提交给国际标准化组织ECMA(European Computer Manufacturers Association),希望为JavaScript定制一套国际标准。至此,我们熟悉的ES标准(ECMAScript)出现。 ES只是一套标准,理论上js可以运行在各种环境里,浏览器只是它的一种环境,但是具体运行还要靠各大厂商实现。ES1.0 ES1.0在1997年发布,基于JavaScript和Jscript制定了一些规范。主要规定了ECMAScript的以下组成部分: 语法, 类型, 语句, 关键字, 保留字, 操作符, 对象;ES2 ES2在1998年发布,对ES1进行了一些小的修订和澄清,但未引入重大新功能。ES3 1999年12月,ECMAScript 3.0版发布,成为JavaScript的通行标准,得到了广泛支持。可以说这一版才是对该标准第一次真正的修改,新增了对正则表达式、新控制语句、try-catch异常处理的支持,并围绕标准的国际化做出了一些小的修改,修改内容包括字符串处理、错误定义和数值输出;第3版也标志着ECMAScript成为了一门真正的编程语言,所有的现代浏览器完全支持 ECMAScript 3。 主要更新和新增功能如下:正则表达式:ES3引入了正则表达式支持,这是处理字符串的一个非常强大的工具。 新的控制语句:switch 和 try...catch 语句,提供了更复杂的控制流选项。 错误处理:引入了try...catch和throw语句,用于异常处理。 新的字符串方法:例如charAt(), charCodeAt(), concat(), indexOf(), lastIndexOf(), slice(), substring(), toLowerCase(), toUpperCase(), 和split()。 新的数组方法:例如concat(), join(), pop(), push(), reverse(), shift(), slice(), sort(), splice(), 和unshift()。 国际化支持:增加了对Unicode的基本支持,以及一些国际化相关的函数。 更严格的错误检查:ES3对某些类型错误进行了更严格的检查,例如在赋值时类型不匹配。 行为一致性:对一些语言特性进行了规范,以确保不同实现之间的行为一致性。 保留字:ES3规范定义了更多的保留字,以避免在未来版本的JavaScript中出现命名冲突。ES4阶段 在ES3发布后的十年里,web开发逐渐兴起,各种更新讨论踊跃而出,ECMA TC39重新召集相关人员共同谋划,结果,出台后的标准几乎是在第3版的基础上完全定义了一门新语言;第4版不仅包含了强类型变量、新语句和新的数据结构、真正的类和经典继承,还定义了与数据交互的新方式。 技术专家委员会成员包括 Microsoft、Mozilla、Google 等大公司;各方对于是否通过这个标准,发生了严重分歧;以 Yahoo、Microsoft、Google 为首的大公司,反对 JavaScript 的大幅升级,主张小幅改动;以 JavaScript 创造者 Brendan Eich 为首的 Mozilla 公司,则坚持当前的草案; 由于各方意见不统一,ES4未能成为正式标准,在ES3发布后的10年里,ES标准并未做大更新。ES5 2009年12月3日,ECMAScript 5.0版正式发布;第5版力求澄清第3版中已知的歧义并添加了新的功能,包括原生JSON对象、继承的方法和高级属性定义,以及严格模式;随着时间的推移,所有的现代浏览器已经完全支持 ES5; 除了ECMAScript的版本,很长一段时间中,Netscape公司(以及继承它的Mozilla基金会)在内部依然使用自己的版本号,这导致了JavaScript有自己不同于ECMAScript的版本号;1996年3月,Navigator 2.0内置了JavaScript 1.0;JavaScript 1.1版对应ECMAScript 1.0,但是直到JavaScript 1.4版才完全兼容ECMAScript 1.0; JavaScript 1.5版完全兼容ECMAScript 3.0,目前的JavaScript 1.8版完全兼容ECMAScript 5;严格模式 JSON.stringify和JSON.parse getters/setters 数组方法扩展(如forEach、map、reduce等) 不可变对象(Object.freeze) 函数.bind方法等重要特性 可以认为,ES5也只是新引入了一些API,真正对前端发展引起巨大变化的,是2015年发布的ES6标准。ES6 2009年,Node.js项目诞生,创始人为Ryan Dahl,它标志着JavaScript可以用于服务器端编程,从此网站的前端和后端可以使用同一种语言开发; 随着开发项目的变大,模块化已经在修订中成为势在必行的内容,在ES6支持模块化之前,社区中讨论出了一套commonjs标准,标准出来后,直接被NodeJs支持。 ECMAScript 6.0(简称ES6)的目标是使得JavaScript语言可以用来编写复杂的大型应用程序,成为企业级开发语言。因此,在2015年发布的ES6做了如下更新:类 模块化 解构赋值 箭头函数 模板字符串 for…of循环 let/const块级作用域 Promise Map/Set Proxy Reflect等ES6+ 为了让标准的升级成为常规流程,任何人在任何时候,都可以向标准委员会提交新语法的提案,然后标准委员会每个月开一次会,评估这些提案是否可以接受,需要哪些改进;如果经过多次会议以后,一个提案足够成熟了,就可以正式进入标准了; 这就是说,标准的版本升级成为了一个不断滚动的流程,每个月都会有变动; 标准委员会最终决定,标准在每年的 6 月份正式发布一次,作为当年的正式版本;接下来的时间,就在这个版本的基础上做改动,直到下一年的 6 月份,草案就自然变成了新一年的版本;这样一来,就不需要以前的版本号了,只要用年份标记就可以了;所以在ES6以后,后面就是ES2016、ES2017等等...
-
软件更新 2.1.52.1.5测试版 导出txt文件支持在其它软件观看,新增导入本地书籍功能,优化更新提示,在应用内即可更新,优化少量BUGhttps://pan.imtwa.top/p/MwD3268GCq/xxRead2.1.5.apk2024-9-182.1.4阅读界面增加多个字体选择,加入背景颜色调色盘,优化少量BUGhttps://pan.imtwa.top/p/XWOomDFhQk/xxRead2.1.4.apk2024-9-112.1.2搜索页面精确展示搜索结果,加入搜索超时取消逻辑,优化少量BUGhttps://pan.imtwa.top/p/NPEai7dHQm/xxRead2.1.2.apk2024-8-252.1.0新增作品分类,新增作品标签,优化书城界面,优化少量BUGhttps://pan.imtwa.top/p/NPEai7dHQm/xxRead2.1.2.apk2024-4-52.0.8使用触底刷新,优化搜索页内容过多卡顿问题,优化少量BUGhttps://pan.imtwa.top/p/NPEai7dHQm/xxRead2.1.2.apk2024-4-42.0.6支持音量长按翻页,使用虚拟列表,优化主页目录加载速度,优化少量BUGhttps://pan.imtwa.top/p/NPEai7dHQm/xxRead2.1.2.apk2024-3-42.0.4新增书源管理,使用并发处理,优化数据加载速度和系统性能,优化少量BUGhttps://pan.imtwa.top/p/NPEai7dHQm/xxRead2.1.2.apk2023-11-112.0.2引入Levenshtein算法,优化搜索结果展示,增加多个书源,搜索结果改为多书源结果,优化少量BUGhttps://pan.imtwa.top/p/NPEai7dHQm/xxRead2.1.2.apk2023-11-082.0.0重构项目代码,新增下拉刷新,新增图片查看保存,新增书架宫格展示,优化书源,优化少量BUGhttps://pan.imtwa.top/p/NPEai7dHQm/xxRead2.1.2.apk2023-11-031.1.2新增导出TXT功能,优化少量BUGhttps://pan.imtwa.top/p/NPEai7dHQm/xxRead2.1.2.apk2023-09-251.1.0新增头像昵称简介自定义设置https://pan.imtwa.top/p/NPEai7dHQm/xxRead2.1.2.apk2023-09-221.0.8书架页面新增左滑删除,新增更新提示,优化界面设计https://pan.imtwa.top/p/NPEai7dHQm/xxRead2.1.2.apk2023-09-211.0.6优化榜单界面,解决遇到连续英文翻页阅读页面显示不完全的BUGhttps://pan.imtwa.top/p/NPEai7dHQm/xxRead2.1.2.apk2023-09-181.0.4加入音量翻页功能,优化少量BUGhttps://pan.imtwa.top/p/NPEai7dHQm/xxRead2.1.2.apk2023-09-041.0.2对书源进行替换https://pan.imtwa.top/p/NPEai7dHQm/xxRead2.1.2.apk2023-08-251.0.0初步完成界面设计,实现搜索、阅读、浏览记录、缓存下载等功能https://pan.imtwa.top/p/NPEai7dHQm/xxRead2.1.2.apk2023-08-25